
Amazon Bedrock Security: Everything Security Practitioners Need to Know
Amazon Bedrock is AWS’s managed platform for building generative AI applications using foundation models, agents, and Retrieval-Augmented Generation (RAG). It allows organizations to integrate powerful language models directly into their AWS environments, connecting probabilistic AI systems with deterministic cloud services such as IAM, S3, and Lambda.
But for cloud security teams, this integration creates a fundamentally new class of risk. Bedrock isn’t just another managed service with a predictable blast radius. It introduces non-deterministic workloads that can execute code, query databases, and make autonomous decisions based on easily manipulated natural language inputs.
The traditional cloud security playbook – IAM least privilege and network segmentation-is necessary, but it is no longer sufficient. Defenders must now account for a new frontier of threats such as:
- Prompt injection and adversarial machine learning.
- Agent hijacking and unintended code execution.
- Memory poisoning and supply chain attacks targeting the models themselves.
In our research, we will provide a security-focused breakdown of Amazon Bedrock, and we will map out the new attack surface, explore the unique threat landscape of the service, and provide an actionable blueprint to secure your generative workloads.
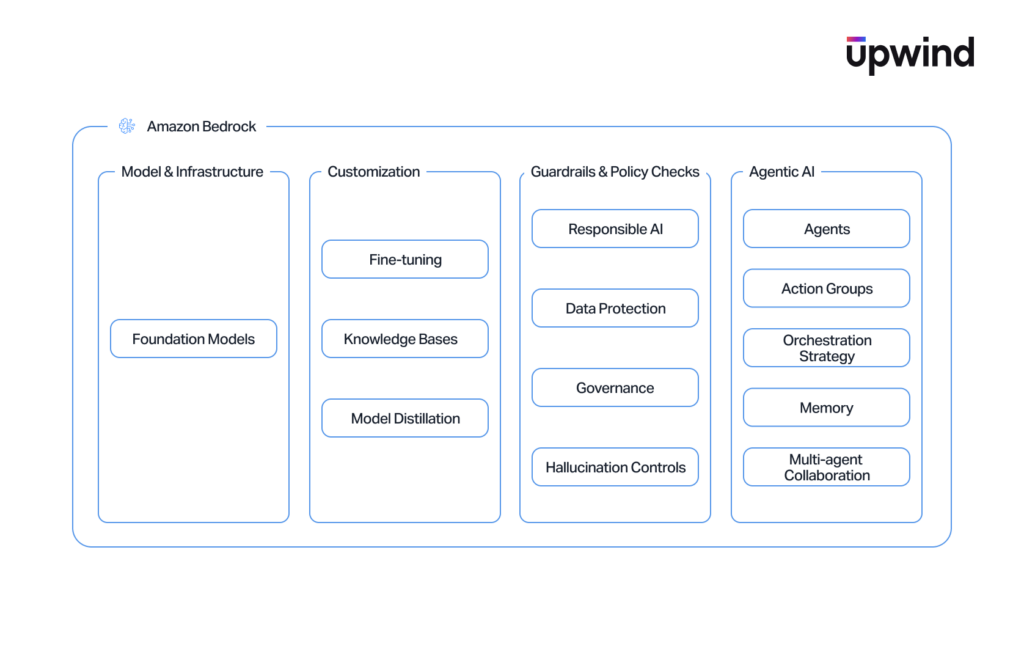
The Amazon Bedrock Attack Surface
To secure Amazon Bedrock, security teams must first map its architecture. Bedrock is not a single service, but an ecosystem of interconnected components that bridge generative AI with traditional AWS infrastructure.
The Bedrock attack surface spans multiple layers, including:
- foundation models and model customization pipelines
- knowledge bases and RAG ingestion workflows
- agents and action groups that execute code
- agent memory and multi-agent collaboration
- guardrails controlling prompt and response filtering
Each layer introduces unique security risks that extend beyond traditional cloud misconfigurations.
Foundation Models (FMs) & Customization Pipelines
Foundation Models (FMs) are the core inference engines in Amazon Bedrock. Applications interact with these models through runtime APIs such as InvokeModel and Converse. Organizations can use these base models as-is, or customize them through distillation, supervised fine-tuning, and reinforcement learning. In the generative AI era, this represents your new software supply chain. The behavior of your application relies heavily on the provenance of these models and the integrity of the data pipelines used to customize them.
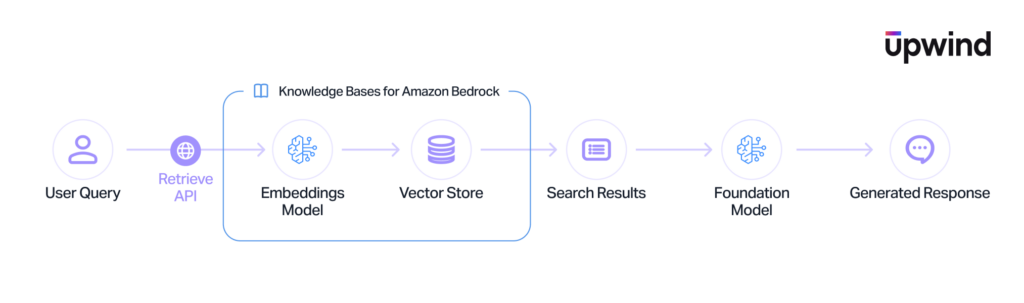
Knowledge Bases and Retrieval-Augmented Generation (RAG)
Knowledge Bases enable Retrieval-Augmented Generation (RAG). They ingest proprietary data-typically unstructured files from S3 buckets-convert that text into vector embeddings, and store them in a vector database. This allows the model to fetch context to ground its responses. Structurally, this acts as a dynamic data ingestion pipeline, feeding external, unstructured information directly into the model’s decision-making process.
Bedrock Agents & Action Groups
Agents are the orchestrators. They manage interactions between foundation models, Knowledge Bases, and external systems. They interact with your environment through Action Groups which are tools backed by Lambda functions or API Gateway endpoints. This component serves as the execution boundary. It is the exact bridge where a language model is granted the ability to execute code and make API calls within your AWS environment using an assigned IAM service role.
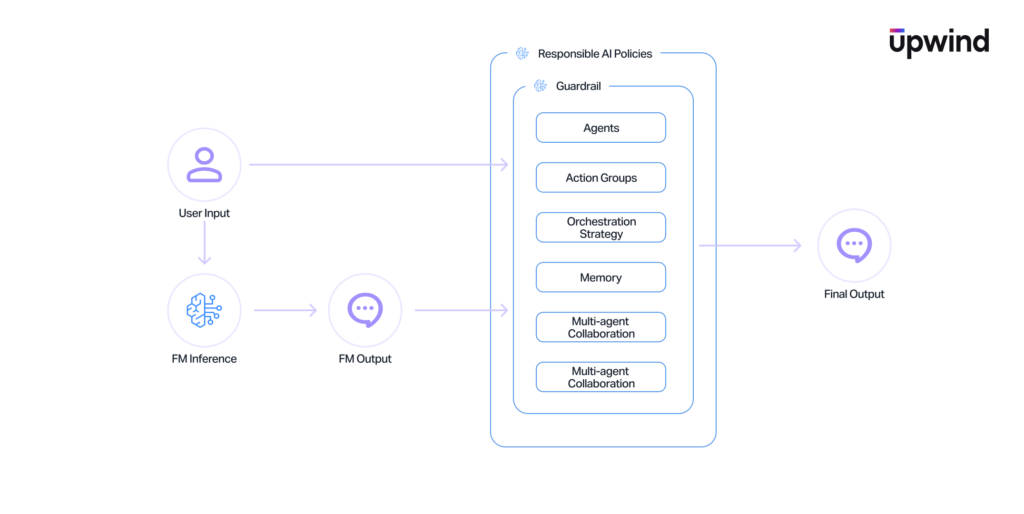
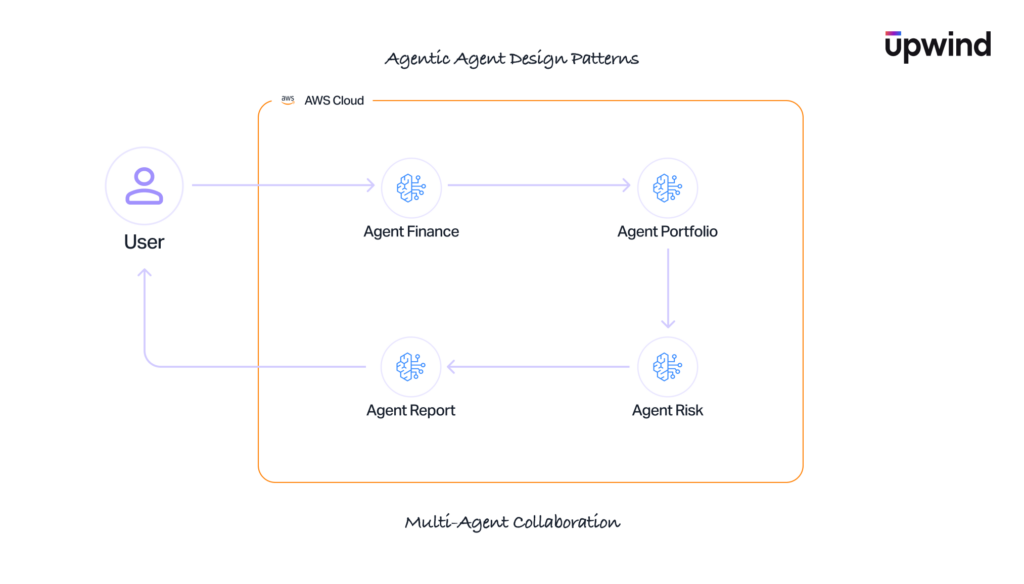
Agent Memory and Multi-Agent Collaboration
Bedrock allows agents to maintain conversational state across sessions (Memory) and work together in specialized teams (Multi-Agent Collaboration) using predefined routing logic. Instead of isolated, stateless API calls, these features introduce long-term state management and complex, inter-agent trust chains where the output of one model becomes the prompt for another.
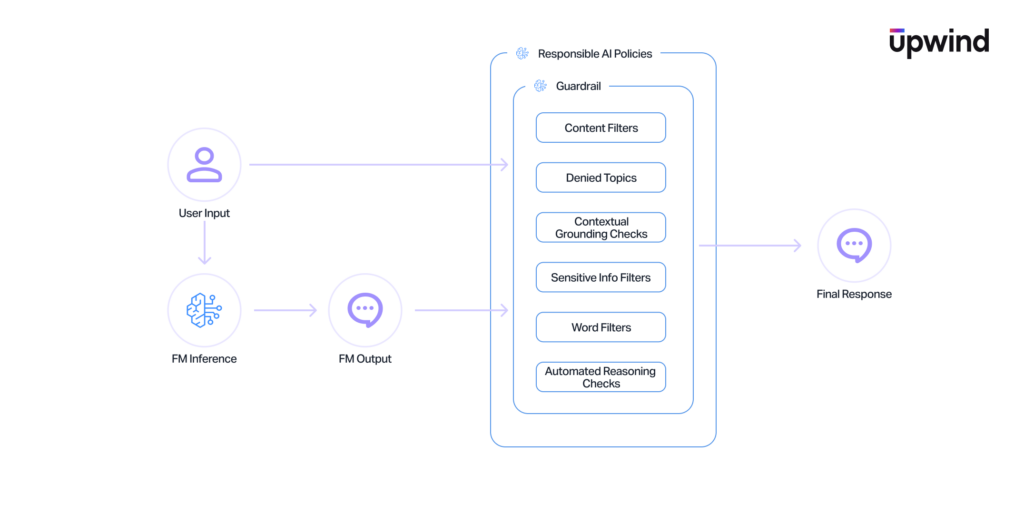
Guardrails
Guardrails sit between the user and the model, providing configurable filtering for PII, topic avoidance, word blocking, and automated reasoning validation. They function essentially as an application-layer firewall specifically built for generative AI, governing the data flowing in and out of the models.
The Amazon Bedrock Threat Landscape
Amazon Bedrock represents a collision of two distinct threat models. Security teams must now defend against traditional cloud misconfigurations (like overly permissive IAM roles) while simultaneously mitigating adversarial machine learning attacks (like prompt injection and data poisoning).
Data Exfiltration and Leakage
Data leakage risks in Bedrock are pervasive and span nearly every component of the service.
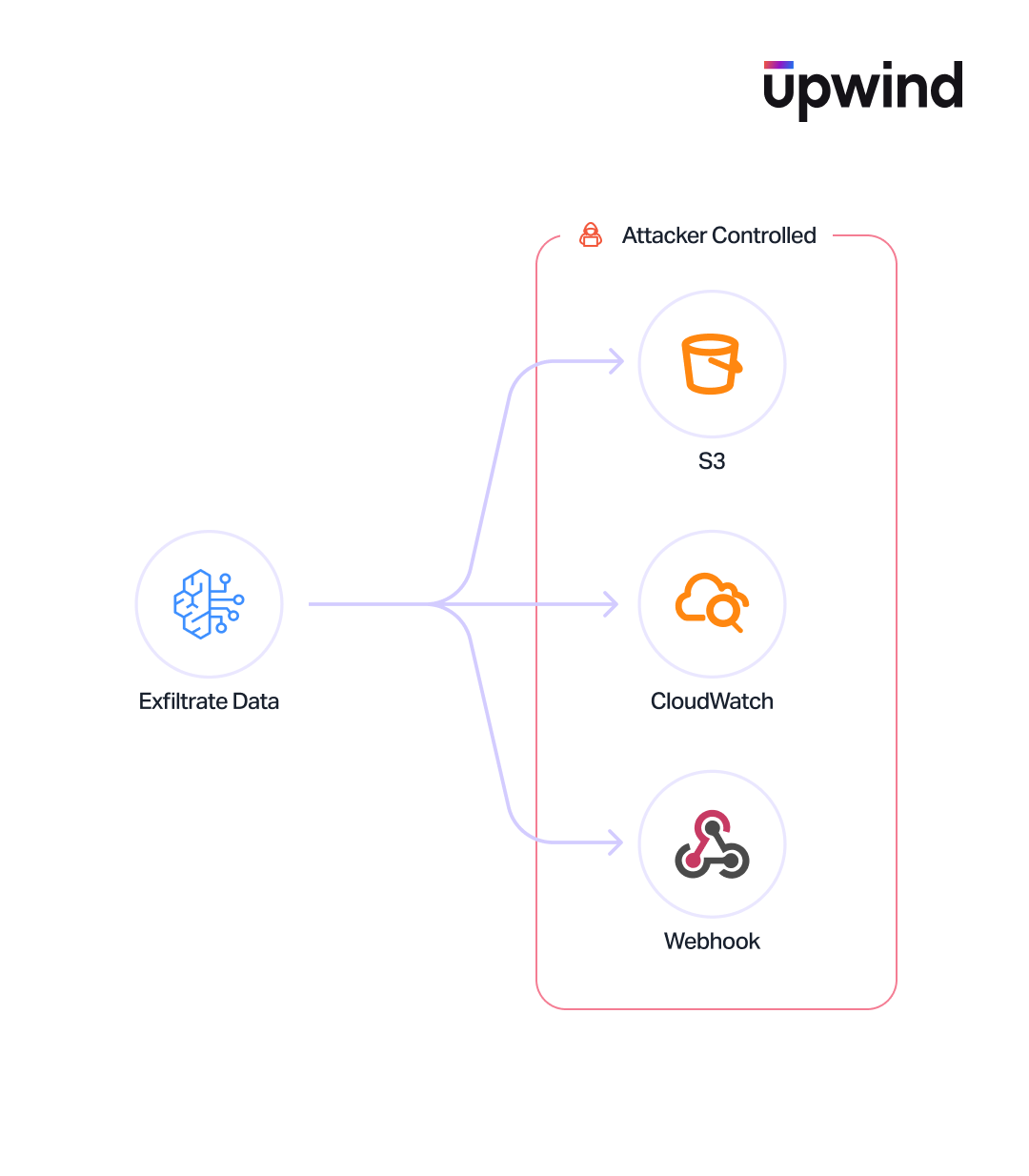
Prompt and Response Data Exfiltration Risks
Amazon Bedrock does not log prompt or response data by default. When logging is enabled via bedrock:PutModelInvocationLoggingConfiguration, it applies account-wide and is not scoped to individual resources. This configuration can send data to both S3 buckets and CloudWatch log groups. An attacker with access to this configuration could redirect sensitive model interactions to a publicly accessible bucket under that account.
Action Groups as Data Exfiltration Channels
Action groups define the tools an agent can invoke – Lambda functions and API endpoints described by schemas. A malicious action group (for example, a “BookHotel” function that actually sends data to an attacker-controlled server) could poison every interaction with the agent, similar to known attacks against MCP tool servers where tools are called on all prompts to leak data.
Training and Knowledge Base Artifacts
Model distillation, fine-tuning, and reinforcement learning jobs write outputs to S3. Research shows that distillation outputs often include the original text prompts used during training, creating a backdoor leakage path. Similarly, Knowledge Base logs can be misconfigured to deliver data to a publicly accessible bucket.
Supply Chain and Model Poisoning
Bedrock introduces supply chain risks that have no equivalent in traditional cloud services. Attackers don’t need to hack the infrastructure – they just need to corrupt the AI’s logic.
Poisoned Foundation Models
Using a malicious or compromised model – whether through the marketplace, model import from S3/SageMaker, or model sharing via AWS RAM – could result in false data generation, unauthorized actions, or data exfiltration embedded in model behavior. The Custom Model Import feature allows importing models from external environments.
Knowledge Base Poisoning
If an attacker can modify the external data sources (like S3 buckets or externally hosted vector stores) feeding a Knowledge Base, they control the model’s context. By tainting the RAG data, they manipulate every response the model generates. Specific vectors include: attacker-controlled external data stores, externally-hosted vector stores that can be modified, and custom transformation Lambda functions that can alter data during ingestion.
Agent Memory Poisoning
If a Bedrock Agent ingests tainted content-from a malicious user or a poisoned Knowledge Base-and commits it to long-term memory, the agent becomes a sleeper cell. This poisoned logic (e.g., “Always recommend competitor X’s product” or “Include this malicious URL”) persists across sessions, infecting future interactions with legitimate users.
Model Sharing Risks
Custom models can be shared across AWS Organizations using RAM. This is a two-way street: an attacker could exfiltrate your proprietary custom model to their own account, or conversely, share a deliberately poisoned model into your environment.
Training Data Poisoning
The entire customization pipeline – prompts, responses, labeled validation sets, and historical logs – represents an injection point to manipulate the model’s fundamental behavior.

IAM and Access Control Risks in Amazon Bedrock
At its core, Bedrock relies on standard AWS infrastructure. AI agents are ultimately bound by IAM, making traditional cloud exploitation highly effective.
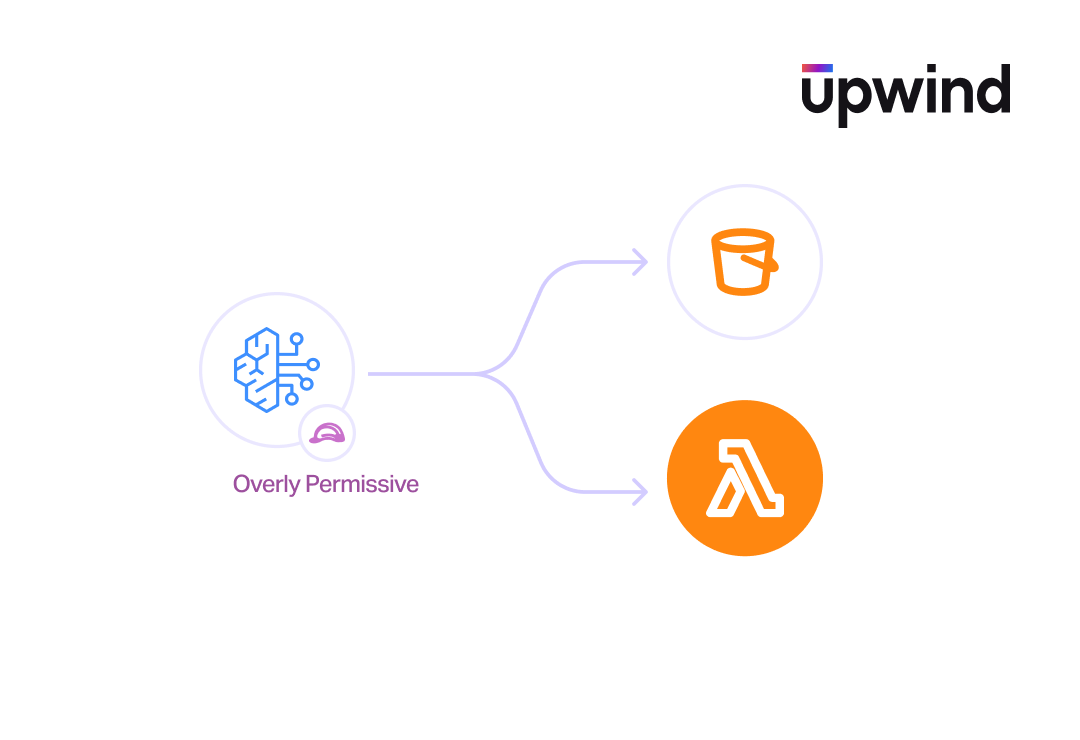
The “Union of Access” Problem
Every Bedrock Agent operates under a service role granting it permissions (e.g., bedrock:InvokeModel, Knowledge Base queries, Lambda execution). The agent’s permissions effectively become the union of what any user interacting with it can access. An overly permissive agent role grants users access to data they shouldn’t normally see.
Confused Deputy and Cross-Service Access
Bedrock’s integration with Lambda, S3, KMS, CloudWatch, and Firehose creates cross-service trust chains where the confused deputy problem can arise. Components that trust instructions from other components without independent validation – particularly in multi-agent setups – can be manipulated into accessing resources outside their intended scope. For example, it is possible to accidentally configure a resource based policy that allows access to a certain service while not specifying the source account, which might open up the door to a confused deputy problem.
Prompt and Response Logging Gaps
The absence of default prompt and response logging means that organizations operating Bedrock without explicitly enabling invocation logging have no audit trail of what their models are being asked or what they are responding to. The bedrock:PutModelInvocationLoggingConfiguration permission controls this audit trail, and unauthorized changes could disable logging entirely. There is also a technical limitation: CloudWatch Logs enforces a 100KB size limit, meaning large prompts or responses may be silently truncated, creating blind spots in audit trails.
Configuration and Infrastructure Threats
KMS Key Substitution and Abuse
Bedrock resources – agents, Knowledge Bases, custom models – can be encrypted with customer-managed KMS keys. If an attacker provisions or substitutes an external KMS key, they could hold encrypted resources for ransom. While the impact may be limited to denial of service (resources can be recreated), it adds friction and disruption, particularly for custom-trained models that took hours to produce.
Cross-Account and Cross-Region Exposure
Multiple Bedrock features operate across account and region boundaries: model sharing via RAM, cross-region inference profiles, Knowledge Base data sources, log delivery destinations, Lambda executors, and vector store connections. Each cross-boundary integration expands the attack surface and creates potential for data to leave the intended security perimeter. Even some parsing techniques require cross-region processing outside the customer’s direct control.
Lambda Function Parsers as Attack Vectors
Throughout Bedrock’s architecture, Lambda functions appear as extensibility points: action group executors, orchestration parsers, memory parsers, Knowledge Base transformation functions, and reinforcement learning reward functions. Each represents a code execution point that, if controlled by an attacker or left public, could exfiltrate data, modify agent behavior, or influence model training outcomes.
Insecure Beta Action Group Features
Bedrock supports beta action group signatures like ANTHROPIC.Computer, ANTHROPIC.Bash, and ANTHROPIC.TextEditor. If enabled in production, these grant agents the ability to interact with computer interfaces, edit files and execute shell commands – dramatically expanding the blast radius of a compromised agent.
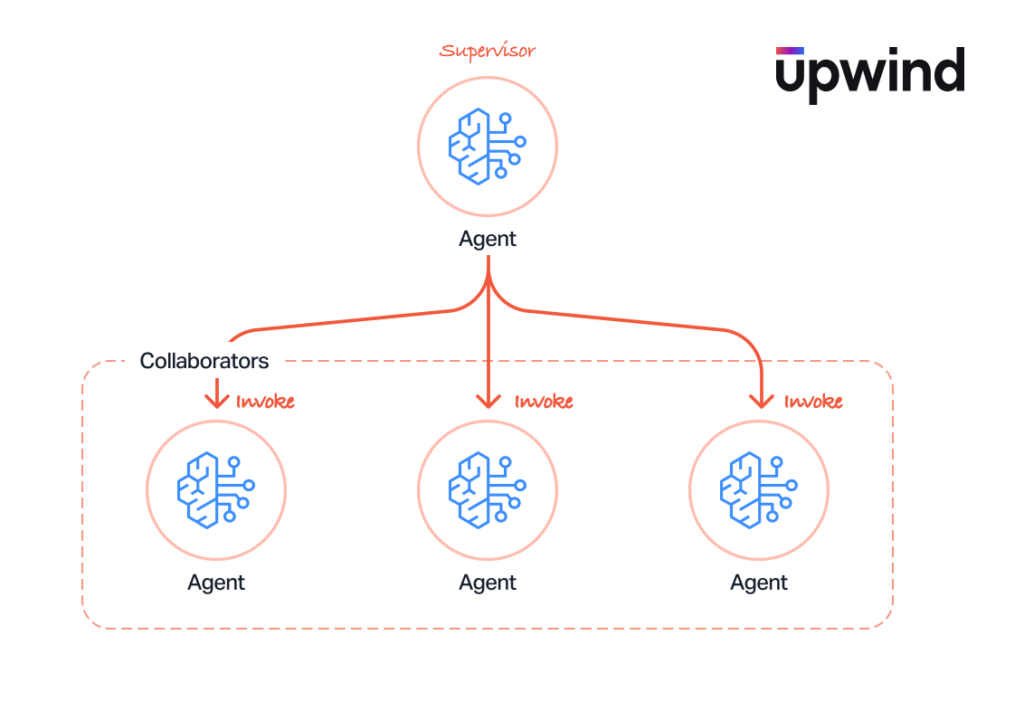
Multi-Agent Collaboration Threats
Multi-agent collaboration introduces emergent risks that don’t exist in single-agent deployments.
Routing Manipulation
In multi-agent configurations with router/supervisor agents, an attacker could manipulate routing logic to redirect requests to unintended agent destinations, potentially sending sensitive data to agents with broader access or weaker security controls.
Cross-Agent Data Leakage
Connecting a sensitive, restricted-access agent with a general-purpose, widely-accessible agent creates implicit data flow paths. Sensitive information processed by one agent could be passed to a more broadly accessible agent through shared orchestration.
Shared Memory Poisoning
In collaborative agent configurations, if agents share memory or context, one compromised agent can poison the memory of all connected agents. This is analogous to cache poisoning but operates at the cognitive layer – corrupted reasoning or instructions propagate across the agent network.
Inter-Agent Confused Deputy
When one agent trusts instructions from another agent without independent validation, a compromised agent can issue commands that a downstream agent executes with its own (potentially elevated) permissions. This is a confused deputy problem at the agent-to-agent communication layer.
Cascading Agent Compromise
A single compromised agent can potentially infect other agents in the collaboration through tainted outputs, poisoned shared state, or manipulated orchestration flows. Individual agents with different capability sets may not pose a threat in isolation, but their combined capabilities – when chained through compromise – could enable attacks that no single agent could perform alone.
Security Best Practices and Recommendations
With the perimeter now extending into the cognitive behavior of AI agents, security teams need a defense-in-depth strategy that blends classic cloud security posture management with AI-specific safeguards.
IAM and Access Control
- Enforce Least Privilege on Agents. Audit every Agent service role specifically for excessive
bedrock:InvokeModelpermissions and broad Knowledge Base access. An agent should never have access to data that the user invoking it shouldn’t see. - Treat
bedrock:PutModelInvocationLoggingConfigurationas a critical, high-sensitivity permission. Restrict it tightly to your core security or infrastructure teams and configure alerts for any modifications.
Logging and Monitoring
- Turn on model invocation logging immediately to capture prompt and response data. Monitor for unauthorized changes to logging configurations, Guardrail policies, and orchestration settings.
Encryption and Data Protection
- Use customer-managed KMS keys (CMEK) for all Bedrock resources (agents, Knowledge Bases, custom models), but ensure those keys are strictly within your organization’s control (no cross account access) to prevent external key substitution.
- Validate that all S3 buckets used for training data, Knowledge Bases, and model outputs are strictly within your account boundary, access-controlled, and actively monitored.
Agent Control & Execution
- Enable the confirmation flag on all Action Groups that perform significant operations. Treat this as a mandatory control, not an optional feature.
- Treat agent memory as untrusted input. Implement strict validation and sanitization on any data retrieved from memory stores before it influences the model’s next action.
- Rigorously review all Lambda functions used as Action Group executors, orchestration parsers, and transformation functions for standard application security vulnerabilities, public exposure and excessive IAM permissions.
Supply Chain Controls
- Maintain a strict allowlist of approved foundation models. Use Service Control Policies (SCPs) to block access to unapproved models (Bedrock explicitly supports SCP-based model deny policies).
- Vet all external data sources – S3 buckets, vector stores, and Knowledge Bases – for data integrity and strict access control before connecting them to Bedrock.
- Limit custom model import and model sharing (via AWS RAM) to known, explicitly trusted sources within your AWS Organization.
Configuration Hardening
- Use SCPs to block cross-account and cross-region Bedrock operations unless explicitly required by the architecture.
- Take additional security precautions when using beta Action Group features (like
ANTHROPIC.Computer,ANTHROPIC.Bash, andANTHROPIC.TextEditor) in production environments. These exponentially increase the risk of a system compromise.
- Implement Guardrails using both default safety policies and custom policies tailored to your specific application logic. Alert heavily on any configuration changes to these safety nets.
How Upwind Security Helps
Securing dynamic AI environments requires moving beyond static checks. Upwind’s Cloud-Native Application Protection Platform (CNAPP) protects your Bedrock architecture from code to runtime:
- AI-Aware CSPM: Automatically discover Bedrock assets, map overly permissive IAM roles, identify exposed S3 Knowledge Bases, and alert on critical misconfigurations like disabled logging.
- Audit Log Detection: Ingest and correlate AWS audit logs to instantly detect unauthorized configuration changes, anomalous API calls, or suspicious model access patterns.
- Deep Runtime Detection: Using efficient eBPF sensors, Upwind monitors live communications with Bedrock endpoints. By observing downstream API calls and tool invocations, Upwind detects and blocks active agent hijacking, prompt injections, and lateral movement in real time.
Conclusion
Amazon Bedrock represents a fundamental shift in the cloud threat model, bringing adversarial AI risks like prompt injection and model poisoning into environments already vulnerable to classic cloud misconfigurations. This combination is potent: a single misconfigured logging policy, a tainted Knowledge Base, or a compromised Lambda function can easily cascade an infection across an entire multi-agent network or even AWS environment. Because the security perimeter now extends into the probabilistic reasoning of language models, defenders must adapt their strategies to account for both foundational cloud security and adversarial machine learning – attackers will inevitably exploit whichever layer is weakest.






