
Building Trusted LLM Security Operations with NVIDIA Nemotron


Executive Summary
Large Language Models now sit directly on the edge of production systems. They respond to API calls, generate code, retrieve internal knowledge, and execute workflows, all while accepting free-form input from users they do not control. That input is not structured, validated, or predictable. It is language. And language can be manipulated.
This changes the nature of application security. Attacks against LLM-powered systems are not delivered through malformed packets, protocol abuse, or injected code. They are written in natural language – a carefully phrased instruction can override a system prompt. A fictional scenario can become a jailbreak. A polite request can conceal an attempt to extract sensitive data. Defending against these attacks means analyzing what a request is trying to accomplish, not just how it is written.
To solve this complex problem, we needed a new approach. That is why Upwind decided to develop a solution capable of defending LLM APIs at production scale.
The Security Challenges LLMs Introduce
In practice, these risks manifest through recurring threat patterns, typically centered around manipulating model behavior or extracting unintended data.
Common objectives include:
- Policy and instruction override, where adversaries attempt to bypass system or developer-defined constraints
- Unauthorized data exposure, targeting system prompts, internal context, or sensitive information accessible to the model
- Behavior manipulation, influencing the model to perform actions outside its intended scope
These outcomes are often achieved through techniques such as prompt injection, jailbreak attempts, narrative framing, or social engineering-style persuasion embedded within natural language requests.
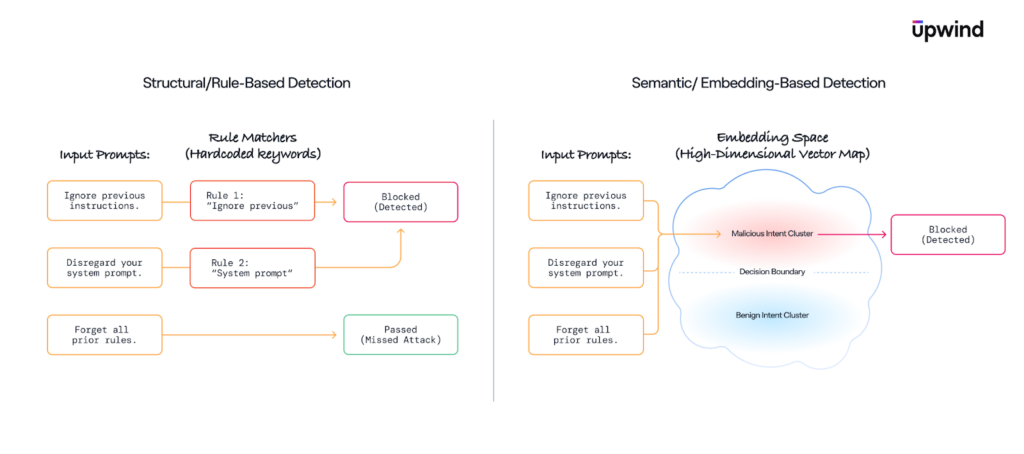
Traditional security controls such as WAF rules, signature-based detection, or static allowlists are poorly suited to these attacks. They lack semantic understanding and tend to break down under paraphrasing, indirection, or minor linguistic variation.
Engineering Constraints That Shape the Solution
Securing LLM-powered APIs comes with a set of constraints that are hard to ignore. Latency matters – multi-second decisions simply aren’t an option. At the same time, running a large language model on every request is not just slow, but prohibitively expensive at scale.
There’s also an asymmetry in the traffic itself. Most inbound requests are either not related to LLMs at all, or are perfectly benign. Treating every request as suspicious quickly leads to unnecessary cost and, worse, false positives that break legitimate user workflows and lower the trust in the system.
These realities make naive solutions impractical. A single heavyweight model, or a pile of rules, does not hold up in production. What’s needed instead is a design that is selective by default, layered in its analysis, and explicitly aware of cost, latency, and the operational impact of getting decisions wrong.
A Three-Stage Detection Architecture
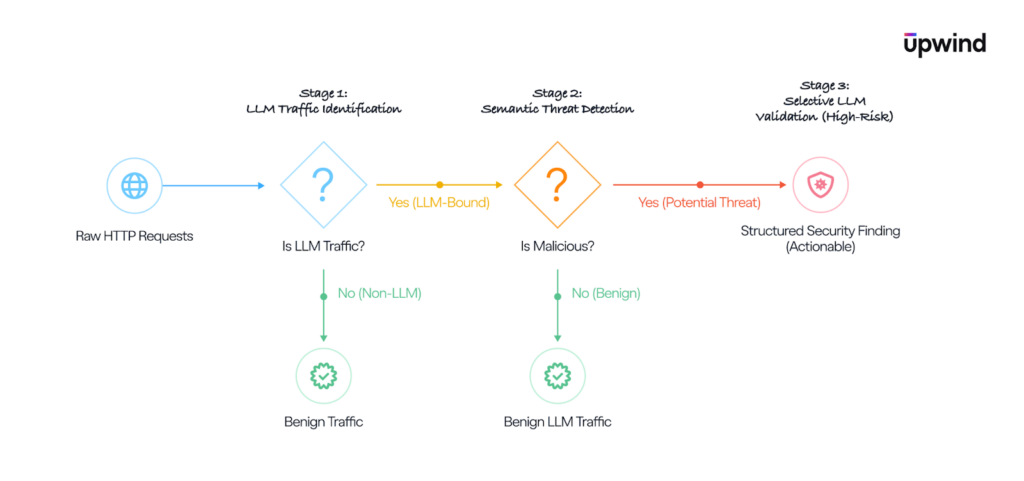
We designed a hierarchical pipeline system, where each stage answers a progressively harder question and only escalates traffic when it actually needs deeper analysis.
Stage 1: LLM Traffic Identification
The first stage answers a very basic, but essential question: is this request even meant for an LLM?
Most production services are not AI-driven at all. In a typical cloud environment, LLM-powered APIs represent only a subset of overall traffic. Applying semantic analysis indiscriminately across all services would introduce unnecessary overhead and cost.
To address this, we begin by identifying which requests are actually destined for LLM-backed functionality. A lightweight machine learning classifier, built on structural and linguistic features, filters out irrelevant traffic almost immediately. This ensures that deeper semantic analysis is applied only where it is operationally meaningful.
In practice, this stage is extremely fast and cheap:
- Inference runs in under a millisecond
- Accuracy is high (99.88%), with strong precision and recall
- There are no external model calls or dependencies
By aggressively filtering early, we make sure that semantic analysis is only applied where it actually makes sense.
Stage 2: Semantic Threat Detection
Once a request is confirmed to be LLM-bound, the next question is straightforward but much harder to answer: is it malicious?
At this point, surface-level signals stop being reliable. Many LLM attacks are phrased indirectly, wrapped in narrative context, or intentionally paraphrased to evade simple rules. Two requests can look very different syntactically while expressing the same underlying intent.
To handle this, we convert the requests into high-dimensional semantic embeddings using NVIDIA’s nv-embedcode-7b-v1 model. These embeddings serve as structured semantic representations of prompt intent and are then used as input features to a downstream neural classifier trained to distinguish benign from adversarial behavior.
Rather than relying on keyword matching or handcrafted heuristics, the classifier learns decision boundaries in embedding space, allowing it to separate malicious and benign prompts based on semantic proximity and intent similarity.
During our evaluation process, we tested multiple embedding approaches. We found that nv-embedcode-7b-v1 offered particularly strong semantic separation between benign and adversarial prompts, especially for indirect jailbreaks, prompt injection attempts, and instruction-manipulation scenarios.
One of the key reasons this model proved effective is its training alignment with code and security-adjacent tasks. Many LLM attacks exploit system prompts, hidden policies, developer instructions, or structured reasoning patterns. A model that understands code-like structure and instruction hierarchies is better equipped to detect subtle manipulation attempts embedded in natural language. This proved especially valuable for identifying adversarial prompts that blend conversational language with instruction override techniques.
Without both the embedding quality and the performance characteristics delivered through NIM, semantic detection would not have been viable in a live API security environment.
This combination of semantic depth and infrastructure efficiency was central to moving from research experimentation to production deployment.
Stage 3: Selective LLM Validation
Even with a strong semantic model, some cases remain ambiguous. To address these edge cases, we apply LLM-as-a-Judge – using a higher-capability model to evaluate borderline prompts and validate earlier detection decisions.
For a small subset of high-risk or low-confidence cases identified earlier in the pipeline, we invoke NVIDIA Nemotron-3-Nano-30B model, deployed with NVIDIA Guardrails capabilities. In this role, Nemotron acts as a reasoning layer rather than a content generator. It evaluates prompt intent, analyzes instruction hierarchy, and determines whether a request constitutes a jailbreak, prompt injection, or policy violation.
This approach allows us to:
- Reduce false positives in ambiguous cases
- Provide structured, human-readable explanations for security teams
- Enforce consistent policy reasoning aligned with established frameworks
Equally important was operational viability. Deploying the model through NVIDIA NIM allowed us to run high-throughput inference with predictable latency and scalability. NIM provided a production-ready microservice layer that simplified integration, accelerated experimentation, and ensured that the LLM could operate within strict real-time constraints. NVIDIA’s optimized inference stack ensures this additional reasoning remains cost-efficient and does not disrupt overall throughput. By reserving foundation-model reasoning for only the most complex cases, we maintain performance while increasing decision confidence.
To ensure this reasoning remains consistent and operationally reliable, we integrate NVIDIA NeMo Guardrails into the evaluation flow. Guardrails are configured with defined behavioral rules and output constraints that guide how the model produces its judgment. Rather than allowing open-ended generation, the model’s responses are restricted to expected classification categories and structured decision formats. Guardrails monitor outputs and validate that they conform to these predefined criteria, enabling consistent, machine-readable verdicts suitable for downstream security workflows.
Measured Results
Across multiple iterations, the system demonstrated consistent performance that aligned with its design goals:
- ~95% precision in malicious prompt detection
- 99.88% precision in LLM traffic identification
- Sub-millisecond inference for machine learning stages
- Predictable cost at scale due to selective model escalation
These results demonstrate that semantic LLM security can operate within strict production constraints, without sacrificing detection quality.
From Detection to Actionable Security
Detection alone is insufficient in modern cloud environments. In distributed systems, a flagged request is only one part of a much larger execution context. Security teams need to understand not just that a prompt was malicious, but where it originated, which service handled it, what data it attempted to access, and how it fits into broader application behavior.
Upwind’s security platform already provides deep visibility into runtime behavior, service identity, and cloud infrastructure context. Integrating LLM threat detection directly into these existing telemetry layers, allows findings to automatically correlate with workload metadata, API exposure, permissions, and execution context.
This means a malicious prompt is not surfaced as an isolated model decision. It is surfaced as an event within a specific service, tied to a specific identity, in a specific environment, with clear insight into what data paths or capabilities were potentially at risk.
LLM detections become part of the broader cloud security posture, aligned with existing runtime and identity signals rather than operating as a standalone monitoring layer. This allows security teams to assess impact and investigate incidents within the full context of the affected workload and its permissions.
Looking Ahead
The rapid expansion of AI-powered applications makes language-based attacks an operational reality, not a theoretical risk. As models grow more capable and deeply embedded in business workflows, adversaries will continue to experiment with new jailbreak techniques, instruction manipulation strategies, and semantic evasion tactics.
Security systems must evolve alongside these models. Detection cannot remain static; it must adapt to increasingly complex interactions between users, applications, and AI agents.
Our collaboration with NVIDIA represents a foundation for that evolution. By combining Upwind’s applied security research with NVIDIA’s embedding models, foundation models, and NIM microservices, we have demonstrated that semantic LLM security can operate at production scale without sacrificing performance or cost efficiency.
Looking forward, continued advances in embedding quality, model efficiency, and inference optimization will further narrow the gap between research-grade semantic understanding and operational defense systems. The ability to deploy high-capability AI models safely and efficiently will become a core requirement for organizations adopting LLM-driven applications.




