

Data poisoning has been called generative AI’s “silent killer.” After all, a little erroneous data in a model that’s hungry for more and more data points has the oversized power to problematically reroute how artificial intelligence responds with manipulated advice and predictions. And that poor advice can undermine business decisions, medical care, or other critical functions across fields.
In talking about AI security, we’ve covered adversarial AI, which includes data poisoning along with other tactics that influence AI systems, making them behave incorrectly. But in this article, we’ll get specific about data poisoning and how to keep malicious data poisoning attacks from undermining the promise of AI.
We’ll talk about the implications of data poisoning for teams and discuss issues like how to be sure Large Language Model (LLM) API or third-party classification models weren’t poisoned upstream, the security consequences of poisoning, and how to gain greater control and trust in data training pipelines.
Refresher: What is AI Data Poisoning?
First, what counts as data poisoning? Most machine learning (ML) models ingest millions of points of data that can’t all be spot-on. But in the case of data poisoning, data isn’t just imperfect; it’s intentionally manipulated by an attacker seeking to corrupt the model’s behavior.
n healthcare, replacing .001% of training tokens (1 million out of one billion) with medical misinformation increased harmful outputs 4.8% in one model. And generating that attack data comes with a nominal cost — between $100 and $1000, depending on model size.
Data poisoning takes place during either training or fine-tuning. It’s purposeful sabotage, and can be so subtle that it often evades detection. There are 2 main types:
- Availability attacks, which degrade overall model accuracy and reliability
- Integrity (or backdoor) attacks, which implant specific triggers that cause targeted misclassification or behavior only under certain conditions.
In both cases, the real concern is that poisoned data often looks harmless. And it can persist undetected through pipelines and versioned training workflows, silently altering the outputs of systems that need to be reliable. The keys? All teams need strong data validation, provenance tracking, and model auditing to tackle an issue where tiny data manipulations create big issues.
Runtime and Container Scanning with Upwind
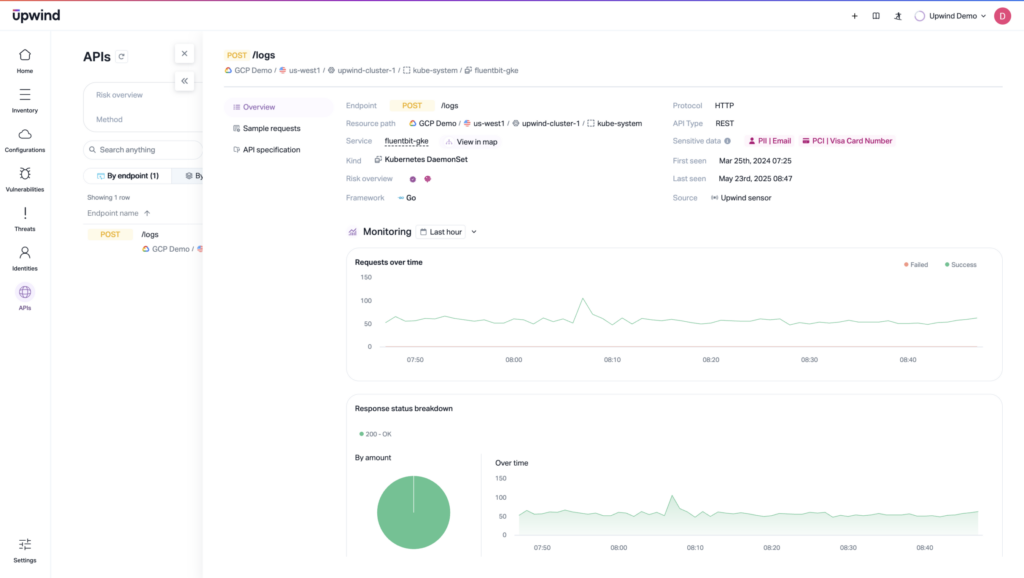
Upwind offers runtime-powered container scanning that goes beyond static analysis, helping detect abnormal behaviors in real time, even when the root cause stems from poisoned AI models. Whether it’s unexpected API calls or unusual access patterns, Upwind contextualizes the threat and pinpoints affected containers for faster remediation and root cause analysis.
Can You Trust What You Didn’t Train?
Most enterprises don’t train large models from scratch; they fine-tune open weights, call commercial LLM APIs, or ingest predictions from third-party classifiers, so they inevitably inherit whatever’s upstream, including any poisoning.
And unlike known vulnerabilities in open-source packages, there’s often no SBOM equivalent for models. Most teams will never see a list of training data sources of what’s been filtered. That means:
- A foundation model may contain dormant backdoors from early-stage training
- A fine-tuned classifier might have been exposed to mislabeled or manipulated examples
- Even “curated” vendor APIs may exhibit biased behavior under specific prompt conditions, with no transparency
When teams don’t train models, they’re left to monitor outputs only. Output monitoring won’t catch targeted integrity attacks that only trigger in rare, engineered cases. And worse, sandboxing can fail to surface subtle poisoning that affects only long-term decision-making pipelines, like drift in recommendations. Consider the serious implications, for example, of that drift in an AI-based fraud detection system.
It’s foolhardy to ever fully trust models trained elsewhere. But teams can quantify trust and reduce uncertainty by:
- Favoring models with transparent training disclosures and reproducible fine-tuning methods.
- Using version diffing to test for behavioral regressions across model updates.
- Treating every model as a potential supply chain risk and integrating it into vendor risk-management strategies and red-teaming practices.
- Scoring risk by function, using less trustworthy models for less critical functions.
Watching for Poisoned Behavior in Runtime
Teams can also monitor how models behave in production. The option gives them more to monitor than model output; they’ll be able to observe downstream effects like unusual API calls, identity assumptions, outbound traffic, or infrastructure changes that can all signal the model is behaving in ways misaligned with expected patterns.
Without access to a model’s internal logic, visibility into the symptoms when models are impacting cloud infrastructure, identity permissions, or data flows in production can help make up some ground.
Here’s how. Look for downstream impacts like:
- The model initiates unfamiliar API calls
- Requests start targeting new cloud regions
- The service identity tied to the model assumes a new role
- IAM paths deviate from baseline behavior
- Model outputs trigger infrastructure changes
- A spike in outbound traffic or new destinations for that traffic
- Certain edge-case inputs consistently cause abnormal infrastructure or identity behavior
- Behavioral drift appears without a business explanation
One early sign is a shift in how applications call APIs. If a model starts triggering requests to services or regions it’s never interacted with before, like making billing calls from a content recommendation service, it’s worth investigating.
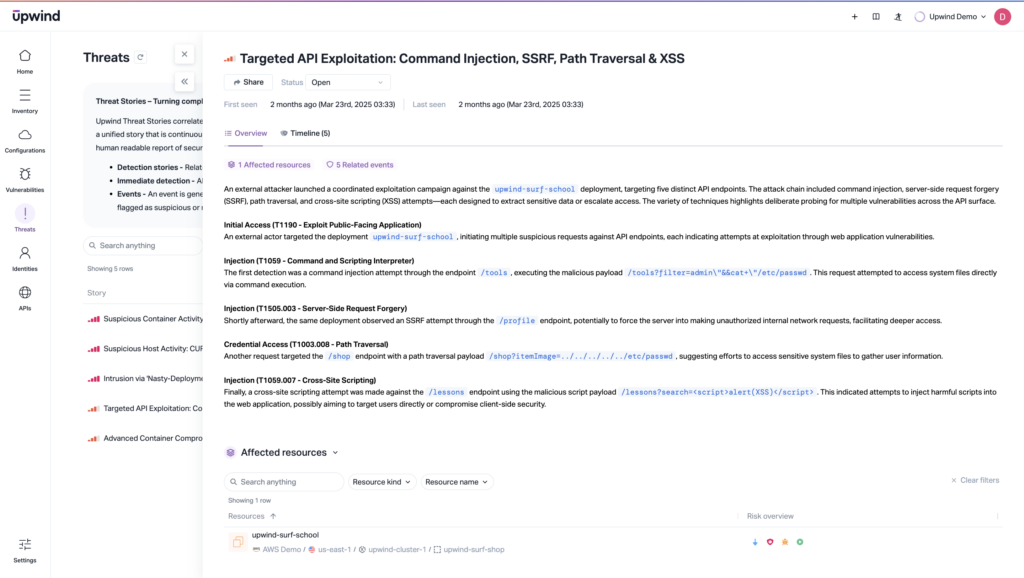
Another red flag is identity behavior that deviates from historical norms. Poisoned models may indirectly cause a service to assume new roles, escalate privileges, or access data it’s never needed before, especially in the over-permissioned and broadly-defined Identity and Access Management (IAM) configurations common in ML models and apps.
By surfacing these patterns, CNAPPs help teams with the visibility to detect the operational fallout of data poisoning. And that’s true even when the root cause is hidden in a fine-tuned model or opaque third-party API.
Where Data Poisoning Can Happen (And What You Can Control)
When teams don’t train their foundational models, there are still ways to meaningfully reduce the risk of poisoned data — if you know where to look. Where can poisoning be introduced, and what cybersecurity controls typically govern those arenas? Let’s make it actionable.
| Lifecycle Stage | Poisoning Risk | Who Owns It | What Security Teams Can Do |
| Foundational Model Training | High, especially in open-source or opaque vendor models | Model vendor / OSS community | Choose vendors with transparent provenance, red-team outputs |
| Fine-Tuning / Transfer Learning | High, as attackers can embed target examples | Internal DS or vendor | Enforce dataset vetting, test with behavioral triggers |
| Inference-Time Inputs | Medium, with prompt injection or feedback loops | End users / applications | Sanitize inputs, restrict reinforcement learning from user feedback |
| Model Deployment and Access | Low for poisoning, but high for blast radius | Infra / Security teams | Enforce least privilege, monitor access to models and data |
| Runtime Behavior and Drift | None for input phase, but it’s where effects are visible | SecOps / CNAPPs / DevOps | Monitor for anomalies, automate responses to behavior that violates policies |
Unfortunately, security can’t control everything about how an AI model was trained, but it can control what happens around the model in production, what data gets fine-tuned, and how inference outputs are allowed to interact with other systems.
What to Do If You Suspect a Model May Be Poisoned
There isn’t a formal playbook for AI data poisoning yet. But it’s already apparent that the response needs to stretch beyond anomalies or model rollbacks. Poisoning impacts models, but it also affects the integrity of the system.
Here’s a step-by-step guide on how to think about containment and investigation as part of an AI attack defense strategy that takes data security and model performance into account:
- Isolate the model: Immediately decouple the model from any production workflows with external consequences.
- Rollback may not mean restore: Reverting to earlier models only helps when poisoned data was introduced during that period. Earlier in the pipeline? It won’t matter. Make sure teams have access to the training dataset lineage to verify.
- Tag the blast radius: Use logs, runtime telemetry, and cloud behavior tracing. Identify what the model influenced — API calls, IAM changes, or user-facing outputs.
- Audit adjacent inputs: If the model was fine-tuned in-house, identify who contributed data or prompts during that window. Include synthetic feedback loops that could have reinforced poisoning.
- Red team the model: Use targeted probes to test for integrity attacks. Poisoned triggers can sit dormant and need obscure prompts to elicit the action or response.
- Classify the event: If the poisoning came from a third-party model, it’s not a data science failure — treat it as a supply chain incident. When it comes to risk governance, these events aren’t much different from something like a compromised SaaS integration.
- Monitor for residual effects: Unlike static software, a model’s behavior can evolve post-deployment. Data poisoning isn’t something that can be patched; it’s an ongoing trust breach that needs continuous monitoring moving forward.
Poisoned models don’t just fail. They also mislead, so team goals go beyond basic recovery. They need to establish trust across systems that depend on that compromised intelligence.
Quantifying Exposure to Data Poisoning Risks
But likely, before heading up a recovery plan, teams want to know what the likelihood is that they’ll ever need it. Of course, data poisoning is possible…but how likely is it, really?
Model poisoning risk is a function of multiple model variables: trust, criticality, blast radius, and observability. While teams can’t eliminate upstream poisoning entirely, they can understand the risk by assigning models a score based on their risk of data poisoning. Look at:
Trust Level
Low-exposure models are trained entirely in-house with vetted data. High-exposure models are fine-tuned by opaque third parties.
Functional Impact
Low-exposure models generate suggestions for internal use. High-exposure models are able to trigger access, pricing, fraud flags, or infrastructure changes.
Feedback Loops
Low-exposure models don’t learn from user input. High-exposure models are continually updated based on user prompts or behavior. LLMs and generative AI open to public input, like ChatGPT, are one such example, where currently, users can opt out of sharing data for training purposes. Chatbots may pose fewer risks if they don’t learn from their interactions with users explicitly.
Runtime Visibility
Low-exposure models are fully instrumented with API and IAM tracing. High-exposure models are a black box. There are no behavioral baselines or drift detection.
Models with one to 2 high exposures are low risk. Monitoring and access controls may be enough. Models with 3 exposures pose medium risks. Add runtime anomaly detection, behavioral diffing, and stricter policy guardrails. Models with 4 exposures are high exposure. These models require provenance, logging for all outputs and side effects, and should have a prepared rollback plan.
Upwind Helps Secure High-Exposure AI Models
Some models trigger access, provision infrastructure, and shape decisions. They need more monitoring. And that’s where Upwind comes in to add runtime visibility to systems around the model, even when the model itself is a black box.
By tracing API calls, identity shifts, and cloud resource access in real time, Upwind helps teams detect the effects of upstream data poisoning before it escalates. So whether you’re protecting vendor-supplied LLMs or fine-tuning internal models, Upwind offers the context to spot subtle behavioral changes and the control to respond faster.
FAQ
How is data poisoning different from adversarial prompts or jailbreaks?
Data poisoning happens during model training or fine-tuning. It changes what the model learns so that it encodes hidden logic, biases, or backdoors.
Adversarial prompts exploit the model at runtime, using inputs designed to nudge it toward unintended behavior. Jailbreaks are a type of prompt attack that specifically bypasses safety filters so models are better able to generate harmful or unethical outputs. These cyberattacks happen after model training. They don’t change how it learns, but they enable it to create unintended outputs.
Is there a scan to tell if a model is poisoned?
There is no signature-based scan that can definitively detect whether a model has been poisoned. Instead, try:
- Behavioral diffing across model versions to detect new edge-case outputs
- Red teaming with targeted prompts designed to trigger potential backdoors
- Runtime observability, like API and IAM monitoring to detect abnormal downstream behavior indicative of upstream poisoning
What does “low-trust” model architecture mean? What does it look like?
A low-trust model architecture assumes that AI models can be wrong or manipulated and builds safeguards for the possibility. It minimizes the blast radius should a model begin to behave incorrectly. In practice, this includes:
- Read-only outputs so models never execute their own suggestions
- Policy enforcement layers so outputs are validated against business logic
- Limited privileges so the model never holds keys, tokens, or write access
- Runtime observability, monitoring downstream behaviors that are suggestive of poisoning
- Version control and rollback, tracking versions, and making sure rollback paths are built in
How does data poisoning relate to AI compliance or upcoming regulations?
Data poisoning calls attention to regulatory norms that are increasingly relevant for AI models, like the traceability of training data, ongoing model behavior monitoring, model strength against manipulation, and the documentation of model risks and mitigation steps.
When a model misclassifies data, the consequences can be severe. Look to Tesla lawsuits that have opened the company to liability when AI systems fail in critical, real-world circumstances, as with autonomous vehicles. The prospect that malicious actors, rather than AI models themselves, could elicit incorrect results, adds a formidable layer of liability for companies.
Compliance risks associated with data poisoning include audits, fines, or disclosure requirements.
Can a poisoned model affect downstream models or chained systems?
Yes. This is one of the most dangerous aspects of data poisoning, which sees outputs from one model become inputs for the next. This happens through fine-tuning, reinforcement learning, and autonomous agent chains. Poisoned models:
- Can inject bias that’s later used to fine-tune other models
- Can feed tainted data to components that are reused across systems
- Can trigger logic in downstream models that assume upstream outputs are legitimate
It’s especially risky in pipelines using LLM orchestration where one model’s response dictates the next model’s behavior. Uncontained poisoning can compound the damage caused by data poisoning.




