

Generative artificial intelligence (GenAI) systems are increasingly ubiquitous — and central to business. Protecting them lags behind their development, leaving organizations exposed to rapidly evolving vulnerabilities unique to GenAI.
After all, large language models (LLMs) can be targets for data exposure, prompt injections that manipulate the model’s behavior, and model poisoning. They’re also public-facing black box assets, with no transparency into how or why they respond the way they do, and they often sit right in the middle of sensitive workflows. That creates both legal and regulatory challenges, as LLMs regularly respond to customer concerns without human oversight. Needless to say, risks are high. And on top of that, defenses are still immature.
We’ve looked into the basics of GenAI security (for securing assets as well as securing GenAI), but when it comes to securing your models, let’s get granular on the real risks.
What is Generative AI Security?
While conventional AI systems predict and classify data within defined boundaries, GenAI models can produce new content, from text to code and images. That’s new. And it presents new opportunities for attackers. Because GenAI is based on probabilistic patterns, it offers open-ended outputs and integrates with natural language interfaces, allowing users to interact with models repeatedly in ways that require minimal skill.
Key GenAI security risks include:
- Prompt injection: Using malicious inputs to manipulate the model into ignoring rules or producing harmful content.
- Data leakage: Prompting the model to reveal potentially sensitive training data in its outputs.
- Model inversion: Making repeated queries in order to reconstruct private data used during training.
- Model poisoning: Manipulating training data to bias the model or introduce backdoors.
- Jailbreaks: Bypassing content filters or guardrails.
- Supply chain attacks: Introducing risks via third-party models, APIs, or plugins.
- Abuse at scale: Exploiting the natural language interface with minimal effort.
Why are GenAI Risks Important?
While AI is increasingly entrenched in business strategies, GenAI is still a cutting-edge technology that’s just breaking into the mainstream for enterprise teams.
According to PwC’s 2024 Pulse Survey, 49% of tech leaders say they’ve integrated AI into the fabric of their overall business strategy.
Despite the growth of LLM models and their mainstream notoriety, just 10% of companies with revenues between $1 and $5 billion have fully integrated GenAI. And that adoption gap is likely caused, at least in part, by concerns over how to secure GenAI resources and the scarcity of talent trained to do so.
GenAI systems aren’t just novel technologies. They’re also dynamic and unpredictable, so they don’t fit into the security approaches most teams and tools are used to. Many GenAI tools lack observability features, so models generate output that can’t always be audited, filtered, or even monitored. This is especially true in AI apps that interact with users in real time, where there may be no clear audit trail.
That’s really key in understanding GenAI’s core risks: the models themselves are points of failure, not simply the applications wrapped around them.
However, ignoring GenAI-specific attack paths increases the chance of compromise, undermines the reliability of models, and can undermine the trustworthiness of every downstream system that depends on GenAI outputs.
For example, if a chatbot leaks private data, it creates a breach of trust and a compliance violation. However, every customer support log, customer record database, and analytics pipeline relying on that model may now contain sensitive, mishandled data and require auditing, resulting in a complex and tangled mess to unravel.
Ultimately, GenAI isn’t a closed system: it’s embedded across workflows and decision-making. So a failure in the model is particularly concerning, as it can spread silently and systematically before it’s even detected.
It’s one thing to understand why GenAI poses unique risks. It’s another to recognize what they look like.
Let’s break down the top risks and how to detect and remediate them earlier.
Runtime and Container Scanning with Upwind
Upwind offers runtime-powered container scanning features so you get real-time threat detection, contextualized analysis, remediation, and root cause analysis that’s 10X faster than traditional methods.
Biggest GenAI Security Risks (and How to See Them Coming)
GenAI cyberattacks don’t follow traditional patterns of exploitation, and that makes them harder to spot using traditional tools. But that doesn’t mean there aren’t ways to shine a light on risks that emerge during their real-world use.
1. Prompt Injection
In a prompt injection attack, an attacker creates model input in the form of prompts designed to override the intended behavior of models. They may tell a model to ignore previous instructions, for example. Prompt injection can successfully make a model disclose private data or perform unauthorized actions.
While prompt injection isn’t always visible to security tools, the outcome often is. Runtime monitoring tools, such as CNAPP, can detect anomalous behavior triggered by user input, even when the user input remains invisible. For example, security teams with runtime protection guarding their GenAI models may see:
- Sudden outbound HTTP requests after an LLM receives a prompt
- A spike in requests to an API from a previously idle service
- A container making calls that it’s never made before
Guard against prompt injection with:
- Application-level sanitation
- LLM proxy gateways with policy enforcement
- Behavioral monitoring post-input

2. Data Leakage
Models can be tricked into releasing pieces of their training data, which can include sensitive customer information or intellectual property. That happens when training data contains sensitive information that the model has memorized and then offered to a user, often inadvertently or due to manipulation. It’s not data exfiltration, so teams can’t scan for file access events, and there’s often no audit trail.
Teams can’t remove what a model has memorized, so if it’s offering up private information, it’s a liability that won’t go away.
Today’s GenAI-savvy security tools can help identify the source of the data training exposure, especially if secrets were in env vars, file systems, or API responses during training.
Guard against data leakage with:
- API-aware data loss prevention (DLP) with LLM-aware filters
- Dataset scanning before training
- Red teaming for output fuzzing
- Runtime CNAPP monitoring for file access
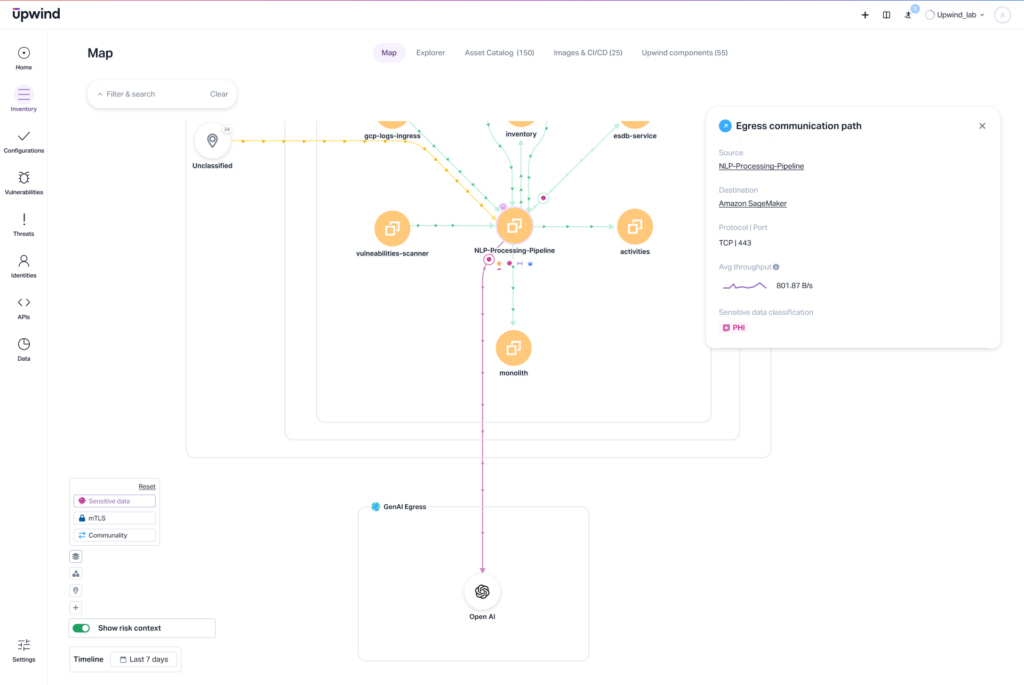
3. Model Inversion and Membership Inference
Carefully formulated prompts can, over time and with experimentation, fool a model into surrendering its training data. Unlike data leakage, model inversion is more about reconstructing parts of the data a model was trained on, and inferring whether a particular record was part of that set.
For instance, a series of leading prompts might release patient information on very rare conditions when queried with the correct symptoms, revealing a case that should have been kept private. The attack carries legal, compliance, and reputational consequences, but attackers often don’t even require system access. And these attacks appear to be regular use, making them difficult to detect.
Guard against it with:
- Identity & usage behavior monitoring
- Query rate limiting
- LLM red-teaming & testing
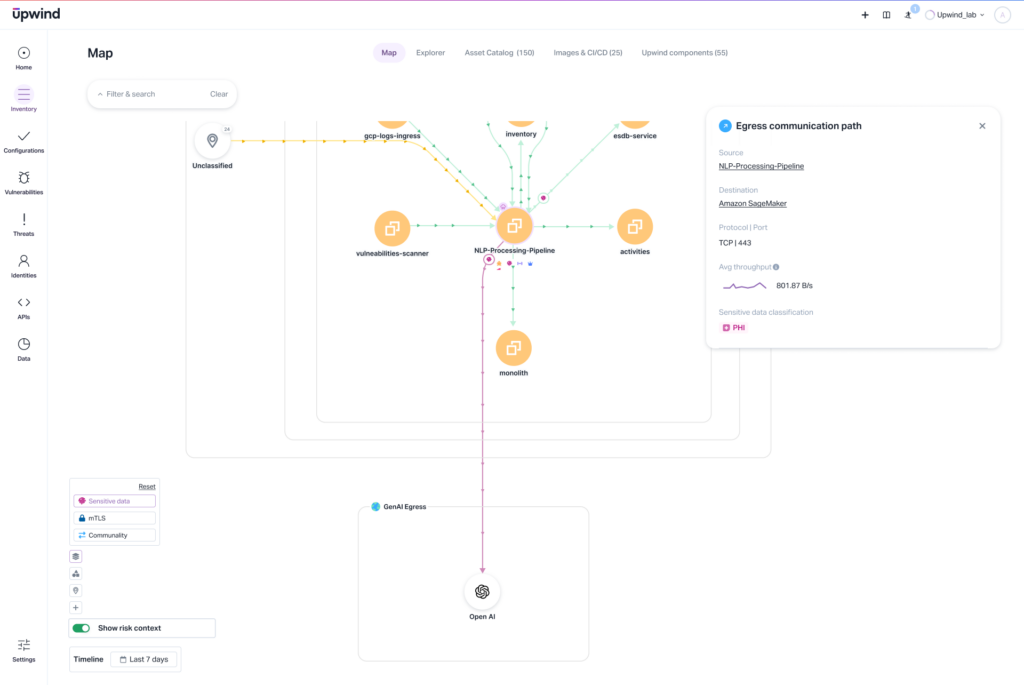
4. Model Poisoning
Attackers can deliberately introduce malicious data during model training or fine-tuning, altering the dataset and therefore the outputs. There are two ways this happens:
- When malicious examples are inserted into training data to bias outputs
- When the attacker embeds a hidden trigger, like a word or phrase, in the model that acts as code to run a malicious script. This backdoor insertion, known as a Trojan trigger, means the model behaves normally almost all the time.
Prevent model poisoning by employing a software bill of materials (SBOM) or CI/CD pipeline view that shows:
- The source of the datasets used in training
- File hash mismatches in training inputs
- External contributor risks flagged during pipeline execution
Guard against it with:
- Supply chain monitoring (data provenance)
- SBOM for datasets and contributors
- CI/CD hardening
5. Jailbreaks (Content Filter Evasion)
Unlike model inversion, jailbreaks aren’t attempts to extract training data. However, they can function similarly, as jailbreakers manipulate models to bypass their own guardrails, which can trick models into saying things they shouldn’t.
Jailbroken models can produce illegal, harmful, or policy-violating output while appearing compliant. For instance, an attacker could ask the model to “pretend” it’s an HR representative compiling and reporting on salary data. If the model complies, it could run afoul of compliance and privacy standards.
As with many GenAI risks, current security tools don’t detect normal-seeming use. But runtime monitoring can catch what happens next, like new processes spawned or calls to suspicious domains after an unsafe response.
Guard against it with :
- Prompt validation/sanitization
- Output monitoring for unsafe responses
- Runtime sandboxing
6. Supply Chain Attacks (Third-Party Plugins, Models, APIs)
It’s not just purposefully manipulated datasets that are an issue with LLM training. Risks introduced by unvetted libraries, models, or plugins, which are especially common in open-source LLM frameworks, too. And they’re just as capable of introducing access control flaws, privilege escalation, or even lateral movement.
Monitor containers, AI libraries, and external model downloads with:
- Dependency scanning
- SBOM validation
- Runtime alerts on new external connections
Guard against it in the same way you would monitor for tampering with datasets. SBOM monitoring and careful attention to sources and changes to dependencies can uncover issues before an attack can cause damage.
7. Abuse at Scale
A key risk of LLMs is that they’re simple to use. Show up, type a prompt in natural language, and watch the model work with your commands. That’s powerful, and it also puts power into the hands of users. That includes malicious actors.
With GenAI, even low-skill attackers can find ways to extract sensitive data and test guardrails.
Monitor for abnormal usage patterns, especially around identity, volume, and geography.
- Sudden spikes in use from unusual regions/IPs
- Anomalous session durations or token counts per user
- Correlation with known abuse sources or suspicious identities
Guard against it with:
- Usage analytics & rate limiting
- Identity monitoring
- Geo/IP-based risk scoring
Again, behavioral analysis and monitoring abnormal usage patterns help teams recognize the impacts of GenAI attacks, though not necessarily the prompts that started it all. And teams can add to their CNAPP security with a Security Information and Event Management (SIEM) platform for correlation across a company’s broader infrastructure, from endpoints to firewalls, identity providers, applications, and cloud infrastructure.
How GenAI Attacks Move Through the Stack
GenAI risks ripple across the cloud infrastructure, spreading from a compromised model to other assets. So for each breach, teams must trace their full journey into systems and through data stores, ultimately learning where and how to stop them.
Here, we’re illustrating that key idea with some of the top GenAI risk scenarios, broken down step-by-step, with a view into which tools can detect or block them at each stage.
| Scenario | Attack Path | Impact | Tool Types to Catch It | Tools that Detect Later |
| Prompt Injection for Data Exfiltration | Attacker inputs a malicious prompt → LLM calls internal API with over-permissioned service account → Sensitive data returned via API → Response shown to user | Internal data exposure, potential compliance violation | CNAPP (IAM & API exposure analysis) | DLP (if configured on egress), WAF (if traffic inspected), manual alert in SIEM |
| Token Abuse / Usage Explosion | Botnet or low-skill attacker generates massive prompt volume via public LLM endpoint → Usage spikes from strange geographies → Rate limits exceeded → Infrastructure cost spike | Denial of wallet, abuse of service, platform instability | API Gateway / Usage Analytics | CNAPPs, even without API monitoring (if runtime alerting on LLM microservice), Identity threat detection, Billing anomaly alerts |
| LLM Generates Exploit Code | User requests payloads or obfuscated exploits → LLM provides functional malware code → Copied into production or test systems without vetting | Malware propagation, RCE, internal compromise | DevSecOps tools (code scanners, policy enforcement) | CNAPP (if deployed workloads behave maliciously), EDR (if code runs on endpoint) |
| Prompt Abuse via Leaked API Key | Stolen or leaked API key used to access private LLM → Prompts submitted without authentication context | Model poisoning, IP theft, token drain | CNAPP (secrets scanning & key lifecycle tracking) | API Gateway (unusual usage from unauthorized sources), Identity platform |
| Prompt Injection into Agent Workflow | Attacker injects a payload into a document or webpage → Agent (LLM-powered tool) reads and executes prompt → Unauthorized action taken (e.g., file deletion, API call) | System manipulation, lateral movement | CNAPP (permissions, workload monitoring) | Other types of runtime behavior monitoring, API logging, and observability tools |
The biggest issues? Many teams think about GenAI security as a “prompt problem.” But GenAI risks move like other modern attacks: they shift from their models quickly, then move through APIs, identities, cloud workloads, and external services. Attacks occur in a predictable order, so stopping them requires multiple layers of defense and knowing which to go to first as various types of attacks play out.
Upwind Traces GenAI Risks Through the Stack
GenAI threats aren’t quarantined in their models. They move through the stack. Security should, too. With protection for cloud workloads, identities, APIs, and infrastructure, Upwind connects the dots. With real-time visibility into runtime behavior, permissions, cloud data access, and network egress, Upwind shows what happened after a prompt is submitted.
From jailbreaks triggering an internal API call or a poisoned model spawning lateral movement, Upwind helps teams see the waypoints of an attack so teams can respond faster, with context, and stop damage before it spreads. And with automation to secure GenAI applications fast, the risks of generative AI just got a lot less challenging.
To see how it works on GenAI assets, schedule a demo.
FAQ
How do I know if a genAI model has already been compromised?
It isn’t always obvious when a GenAI model has been compromised, especially with subtle attacks like poisoning or model inversion. Even with public models like ChatGPT, attackers have demonstrated how subtle prompts can manipulate behavior or coax out sensitive responses, so ultimately, continuous monitoring is the best approach to staying on top of model behavior.
But there are behavioral and environmental clues that can mitigate attacks in progress as well as spot some red flags before they threaten application security and data privacy:
Look for signs like:
- Unexpected or policy-violating outputs from the model, such as those revealing internal data
- Sudden changes in model behavior after fine-tuning or data updates
- Prompts that consistently trigger suspicious or harmful responses
Unusual API activity or system calls originating from the LLM’s environment - Identity or service accounts making high-volume or abnormal prompt requests
- External datasets or unverified contributors in your training pipeline
What’s the difference between monitoring LLMs and securing them?
Monitoring LLMS means observing their behavior, but that doesn’t actively address threats as they happen — it may simply see and acknowledge them. Here’s are the key differentiators:
- Monitoring tracks prompts, outputs, and usage patterns for visibility. But many attacks look like normal use.
- Monitoring tools detect anomalies but don’t block unsafe outputs.
- Monitoring is reactive and therefore ideal for audits, logging, and post-incident reviews.
- Securing enforces guardrails, access controls, and response policies.
- Security tools can sanitize prompts, rate-limit abuse, or sandbox actions.
- Security is proactive and was built to prevent jailbreaks, leaks, and misuse before they happen.
Can I use CNAPPs to stop a GenAI attack at the prompt level?
No, CNAPPs can’t stop GenAI attacks at the prompt level, though they play a role in catching what happens next. Prompt-level defenses require LLM-specific tooling, like LLM gateways or content moderation layers.
CNAPPPs monitor runtime behavior, identities, and egress traffic tied to GenAI workloads. It can detect effects of attacks, from API calls to lateral movement and data access. That’s still incredibly useful, since prompt injection, jailbreaks, or poisoning may look like regular use until they trigger more dangerous actions later in the attack cycle. Use CNAPPs to monitor how GenAI risks spread through infrastructures, but consider pairing them with upstream tools that inspect and control LLM input and output itself.
What if my LLM is open-source or externally hosted?
That gives teams less control, but not less responsibility. They’ll need to inspect their systems and data regardless. Teams will need to:
- Monitor how the model is used even though they won’t be able to see inside it.
- Use proxy layers to log and filter API requests and responses.
- Use input/output validation tools to protect against prompt injection and data leakage.
- Utilize CNAPP workload monitoring to track the behavior of workloads that interact with the model.
- If fine-tuning the model, teams must scan and verify datasets themselves.
- Consider rate limiting, identity access controls, and content moderation for hosted APIs.
It’s all about protecting the surrounding environment. Without controlling the internals, teams can still take care to integrate the model into their own systems so models are less likely to fall prey to risks that help them move downstream, affecting APIs, identities, workloads, and data.





