

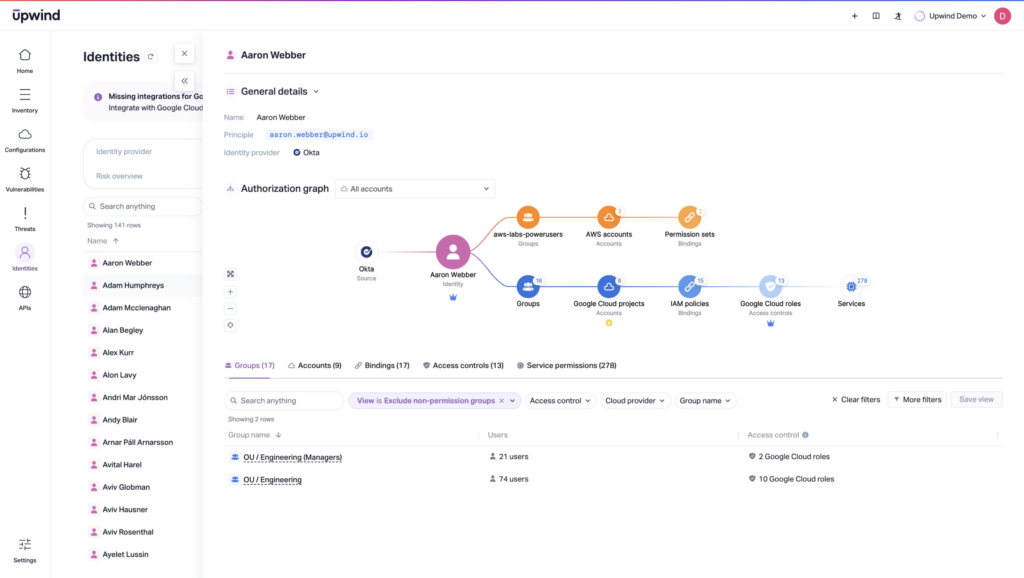
Attackers access cloud systems through vulnerabilities like misconfigured Identity and Access Management (IAM) roles, public buckets, or exposed secrets. But they don’t stay in those initial entryways for long. The time it takes cyberattackers to “breakout” of their initial locations and move laterally across a cloud system is called “breakout time.” And it shapes cyberdefense strategy, since organizations must engage in a race against attackers to shut down secondary access before cyber criminals find and exploit it.
Teams need fast signals — but less noise to sift through.
They need to understand the paths most likely to be taken by attackers deeper into their ecosystems.
Most importantly, they need to know that if an attacker is detected upon initial entry, how long will it take until that alert is addressed and systems are contained? And how do they shave minutes off their average?
Cloud Detection and Response (CDR) is their stopwatch. So let’s talk about how to make sure the team always has more time than the attacker.
What is Breakout Time?
Breakout time was initially coined in the context of nation-state hackers moving from an initial compromised endpoint to other systems on the network, in a time when that referred to on-premises and hybrid networks.
One of the best-known examples of a cyber breakout is Stuxnet, the malware that infiltrated Iran’s nuclear program in the late 2000s. Designed to sabotage enriched uranium centrifuges at the Natanz storage facility, Stuxnet moved from a USB device, using multiple zero-day vulnerabilities, and eventually altered industrial process, all while avoiding detection.
Stuxnet triggered international scrutiny. It was investigated by the International Atomic Energy Agency (IAEA), but ultimately demonstrated that cloud system breakouts could carry catastrophic consequences. While the stakes aren’t always that high, the architecture and privilege paths that enabled Stuxnet’s lateral movement mirror those that modern cloud attackers continue to exploit.
Further, cloud environments have made breakout time faster, since automation and API access accelerate an attacker’s ability to move through the environment.
In Microsoft’s 2022 Digital Defense Report, the average breakout time was 79 minutes, with the fastest observed breakout taking just 20 minutes.
Why the race? The cloud infrastructure itself makes a breakout easier than it was previously, and that puts the onus on defenders to hurry to detect and block attacks. After all, attackers have these cloud-based realities on their side:
- Overly permissive IAM roles
- Stolen or exposed tokens
- Flat network architecture
- Misconfigured storage or secrets
- Federated and cross-account access
- Lack of real-time monitoring
Runtime and Container Scanning with Upwind
Upwind offers runtime-powered container scanning features so you get real-time threat detection, contextualized analysis, remediation, and root cause analysis that’s 10X faster than traditional methods.
Slowing Breakout Time
Teams can’t count on thwarting initial access. But even after it happens, they can slow an attacker’s ability to escalate or move laterally. The longer it takes a threat actor to break out, the more time teams have to detect and contain the threat. What can they do?
Enforce Least Privilege Everywhere
Cloud environments can be littered with roles that carry excessive permissions, many granted temporarily but never rolled back. Least privilege is the first line of defense against an attacker’s movement.
Restrict IAM roles to exactly what’s needed per service. Rotate temporary access tokens frequently. Finally, use deny-by-default, especially for cross-account actions.
Segment the Network Intentionally
Flat network topologies simplify lateral movement, so segment by account, Virtual Private Cloud (VPC), and subnet, then apply granular security groups, forcing attackers to cross hardened boundaries.
Separate dev, test, and production workloads at the account or organizational levels. Lock down peering connections. Use service meshes or identity-aware proxies to control internal traffic.
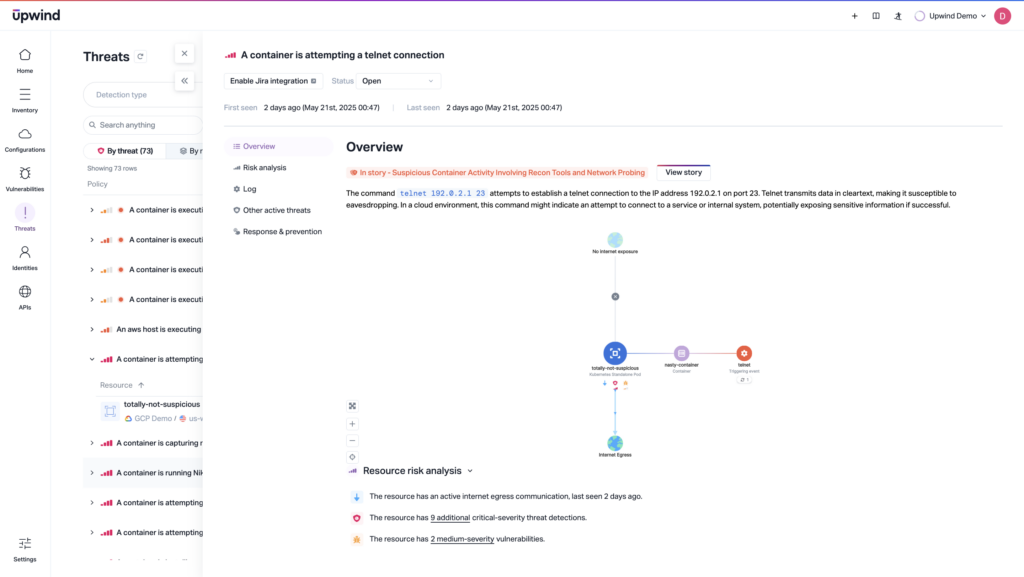
Use Runtime Behavior Monitoring
Breakout behaviors, including those triggered by cloud-deployed malware, can be visible in process-level actions. Behavioral runtime monitoring watches what your workloads do once deployed.
Watch for unusual system calls, binaries, or privilege escalations. Identify containers spawning shells or connecting to unusual endpoints. And correlate behavior with cloud-native context to identify improbable communication between resources.
Apply Just-in-Time Access Controls
Long-lived credentials and pre-provisioned admin roles favor malicious actors. Instead, try ephemeral access to shut down how long a role can be used, even if it’s compromised.
Use identity providers (IdPs) to issue time-limited access. Require multi-factor authentication (MFA) for privilege escalation. Then, enforce approval workflows for high-permission actions.
Automate Detection-to-Containment Pipelines
When an attacker can move in less than 30 minutes, detection alone won’t do the job. The real goal is automated enforcement that shrinks a team’s mean time to respond (MTTR).
First, create predefined playbooks for suspicious behavior. Quarantine workloads, restrict network egress, or freeze activity, and notify human analysts with contextual data, not simply alerts issued in a vacuum.
Secure the Developer Toolchain
Breakout time gets shorter when attackers land in a CI/CD environment with hardcoded secrets or wide permissions, so treat the pipeline like you would a production environment to discourage attack paths that run through the supply chain.
Audit tokens and credentials used in public. Harden runners and enforce build-time Role-Based Access Control (RBAC). And remove unnecessary write access to registries and artifact stores.
Common Breakout Paths and Risk Factors
Not all breakout paths are created equal. Besides, it’s not always possible or efficient to spend time trying to shut down every route out of every entry point. Here are some of the most common cloud lateral movement routes. Blocking pathways can significantly slow an attacker’s breakout time, giving teams the leverage they need to shut down a breach before it spreads.
| Breakout Path | How It Starts | Detection Tips | Defensive Moves |
| IAM Role Assumption | Compromised token or weak trust policy | Look for unexpected STA:AssumeRole calls | Use least privilege and external ID conditions |
| Public S3 Bucket Access | Misconfigured bucket | Monitor access to buckets from unusual IPs | Enforce private-by-default S3 settings |
| Container-to-Host Escape | Exploited vulnerability or misconfigured container | Watch for suspicious system calls and shell spawns | Apply runtime enforcement |
| CI/CD Pipeline Pivot | Exposed secrets or over-permissive runners | Detect use of build tokens in new contexts | Harden the pipeline and restrict secrets |
| Flat VPC Traffic | Lack of a subnet or SG isolation | Monitor traffic patterns between unrelated services | Use microsegmentation and SGs tightly |
| Federated Identity Abuse | Compromised IdP, broad trust relationships in IAM, identity misconfigurations | Watch for unusual federated logins or policy attachments | Audit identity federation flows frequently |
Breakout happens in multiple steps. It’s about a combination of weak entry points plus an overly trusted infrastructure, for example, that creates the fastest route to compromise.
It might look like a low-privilege user with a stolen session token (a low risk on paper) meeting IAM trust policies that allow broad role assumption without external ID validation, allowing users to transition instantly into admin accounts. Likewise, the combination of flat VPC architecture with exposed S3 buckets creates a silent breakout path, as attackers never need to elevate privilege.
One of the fastest routes to breakout involves federated identity combined with over-permissioned IAM roles. If the cloud environment trusts an external IdP, compromises upstream can result in immediate high-privilege access. From there, access to a CI/CD runner or deployment script with hardcoded secrets can allow full workload control, skipping traditional lateral movement entirely.
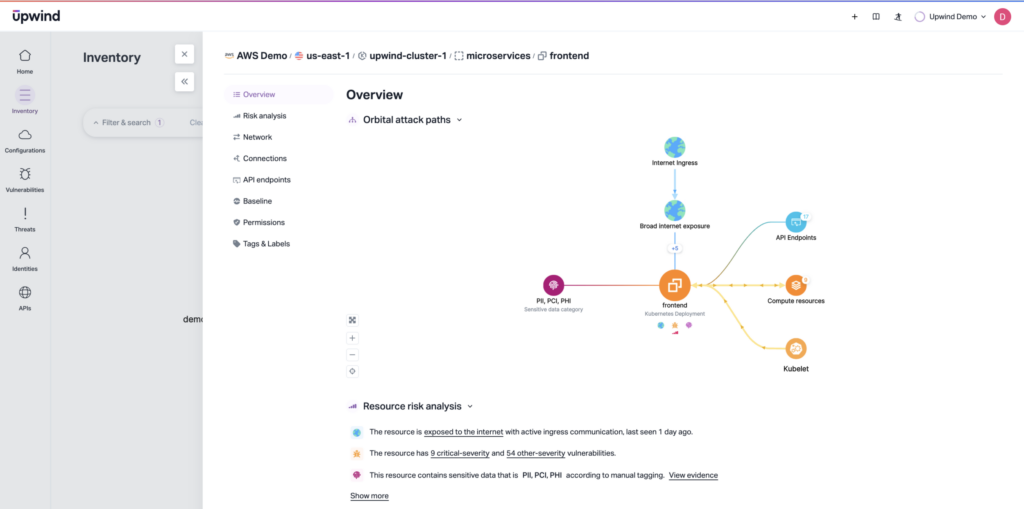
Another risk vector involves container workloads connected to flat networks. Once inside a pod, attackers who escape the container or abuse misconfigured service-to-service permissions find they can easily access metadata endpoints, extract tokens, and assume roles, even those unrelated to the original workload. If service mesh rules or runtime monitoring aren’t used, this type of breakout might go unnoticed until sensitive data is already accessed or modified.
Combining these weaknesses is the norm in breakout patterns. However, teams that can visualize the intersections of weaknesses with paths to their sensitive data and workloads are better positioned to lock them down proactively. It’s not just about a single misconfiguration — attackers see multiple weaknesses as stepping stones in a breakout chain that includes identity, network, and runtime conditions.
Measuring Response vs Breakout Time
Detecting cyber threats is non-negotiable. But detecting them fast enough is how organizations beat breach attempts. With the average amount of time it takes an attacker to pivot being less than 80 minutes, how can teams know whether they’re able to beat the clock?
What to Measure
Breakout unfolds in stages, not in a single explosion. So, evaluate containment defenses in the same way. Start by measuring:
- Time to detect: How long until a signal from a CNAPP or standalone CDR system flags a suspicious behavior like role assumption or runtime drift?
- Time to triage: Once detected, how long does it take the team to verify and escalate it?
- Time to contain: How quickly can the system isolate the workload, revoke credentials, or disable a role before an attacker pivots?
- Time to recover: How long does it take to restore normal operations and access to workloads without introducing more risk?
Response Benchmarks
Not all detections matter will block an attack but the ability to correlate them, escalate those that represent true risks, and act on them quickly, will. Here’s an example of target times to move through the phases of response in order to stay ahead of the ticking clock of breakout time.
| Response Stage | Target Time | What to Track | What’s at Risk if It’s Missed? |
| Detect anomalous role assumption | <5 minutes | Alerts from CNAPP or CDR on role behavior | Attacker gains elevated or cross-account access |
| Isolate compromised workload | <10 minutes | Automated quarantine or kill signals | Attacker executes or spreads in runtime |
| Revoke federated session | <15 minutes | Identity-level response automation | Persistent access from trusted IdPs |
| Human triage (if needed) | <30 minutes | Analyst acknowledgement of decision window | Alert backlog and incomplete containment |
| Full, system-wide containment | <60 minutes | All active paths blocked, logs frozen | Breakout likely already occurred |
Many teams collect logs and alerts, but few map them to when action actually happens. Map audit delays in addition to detection. If the CNAPP says an IAM risk was detected at 12:01, and the role wasn’t disabled until 1:17, that’s a 76-minute breakout window.
To uncover delay gaps, run tabletop exercises that simulate attacker behavior across cloud identities and services. Walk through realistic scenarios: What happens if a low-privilege user suddenly assumes a high-trust role? Who gets notified? What’s the first action taken, and how long does it take?
Even better, inject synthetic test events into the environment. Trigger a fake high-risk behavior, like a suspicious role assumption, and watch what the detection and response stack actually does. Are alerts correlated? Is automation triggered? Does the alert disappear into a backlog of lookalikes? Red-teaming for alert latency offers measurable insight into whether current systems are fast enough to beat breakout.
Ultimately, the question to ask is: would the security team have stopped this attack, or just watched it happen?
Upwind Shrinks Breakout Time With Runtime Detection
As a CNAPP with built-in CDR at runtime, Upwind gives teams visibility into workload behavior, identity activity, and privilege escalation as it happens. Correlating IAM, runtime, and network behavior in real-time means faster detection without piling on alerts that drown analysts without speeding incident response. It means automated cybersecurity response paths that shut down escalation in seconds. With a complete understanding of attacks across multi-cloud, hybrid, and on-prem assets, Upwind is how teams see what’s happening and stop it in time.
Want to see how real-time context changes the race against breakout? Schedule a demo.
FAQ
What’s the difference between breakout and dwell time?
Breakout is the time it takes for an attacker to move laterally from their point of access to other systems, roles, or environments within an organization’s cloud (it averages about 80 minutes). It’s the time between the first compromise and the first escalation or pivot, a key measurement of how fast attackers can expand their reach, representing the time in which organizations can prevent a breach in progress before any data is compromised.
Dwell time is the length of time an attacker remains in the environment without being detected. If a breakout is never detected, dwell time can far outstrip breakout time, with attackers persisting in an environment for minutes to hundreds of days (with the median around 2 weeks). Lengthy dwell times suggest that a system’s defenses are missing key signals.
Can CNAPPs detect a breakout in progress, or just posture?
Look for a CNAPP that includes runtime detection, not just posture management, for the ability to detect breakouts in progress. With a CNAPP that integrates CDR, organizations can correlate identity, network, and workload behavior to identify lateral movement as well as simple misconfigurations. That’s because breakout detection requires being able to see:
- Unusual IAM role assumptions and privilege escalation
- Sudden lateral traffic between previously unrelated cloud services
- Runtime anomalies from shell access to outbound connections
- Use of temporary credentials or tokens in unexpected contexts
- Cross-account or cross-region API activity outside normal baselines
Which breakout path should we prioritize first?
If you had to pick a single breakout path to prioritize first, look for the common, high-speed, hard-to-detect path responsible for multiple cloud breakouts: IAM role assumption without condition enforcement. It’s when attackers compromise a low-privilege identity (via token theft, phishing, or exposed credentials) and organizational IAM roles allow them to assume higher-trust roles without external ID, IP restrictions, or session tags. That lets attackers pivot instantly to higher-privilege roles, even across accounts.
To get started, audit role trust policies for overly broad assumptions and enforce conditions, like MFA, source IP, session tags, or external ID, when possible.
How do I simulate a breakout event safely?
It’s safer to simulate breakout events in non-production environments using these tactics:
- Simulating IAM role assumption by creating a low-privilege role that assumes a higher one and observing detection capabilities.
- Injecting runtime anomalies that open a shell or make outbound calls.
- Simulating lateral movement, sending traffic between isolated VPCs or services to test segmentation rules and alerts.
- Using a breach and attack simulation (BAS) tool to mimic attacker behavior safely.
In a production environment, you’ll test the detection pipeline, validate playbooks, or run a controlled red or purple team exercise. Avoid modifying IAM roles, injecting real traffic, or running containers with altered behavior in production.
How can attackers break out without escalating privileges?
Attackers can exploit overly permissive configurations or misused trust relationships to break out of initial access points without escalating privileges. Common paths that don’t require escalation are:
- Role chaining: Where low-privilege identities assume other roles due to broad trust policies.
- Flat networks: In which open VPCs allow east-west traffic between workloads
- Exposed data stores or secrets: Where attackers access S3 buckets or endpoints that hold credentials for other services.
- Misconfigured CI/CD pipeline integrations: Where low-access users can trigger builds and deployments that run with higher privileges.





