
When cloud security breaches happen, teams are inevitably faced with one key question: Whose fault was it? On Amazon Web Services (AWS), the answer depends on how well you understand the platform’s Shared Responsibility Model, a foundational, but often oversimplified, framework that outlines who secures what in the cloud.
We’ve already explored how to secure containers on AWS and how ECS, EKS, and Fargate differ in orchestration and architecture. In a broader primer, we’ve also shared an overview of what the shared responsibility model in cloud security means, no matter which cloud service teams use. In this article, we’ll step outside the container lens to explain how Amazon’s Shared Responsibility Model plays out across different AWS services, highlight common misinterpretations, and detail how responsibilities shift in scenarios like containerization, serverless, and multi-cloud environments. If you’ve ever assumed AWS handles something it doesn’t — or vice versa — this breakdown can help.
What is the AWS Shared Responsibility Model?
The AWS Shared Responsibility Model defines which security tasks AWS handles and which are the customer’s responsibility in a cloud computing environment. AWS secures the cloud infrastructure — including the hardware, networking, and virtualization layer — while customers are responsible for securing what they build on top of it.
Within AWS, the Shared Responsibility Model varies depending on the type of cloud service used, whether it’s Infrastructure as a Service (IaaS) like EC2, Platform as a Service (PaaS) like AWS Elastic Beanstalk, or Software as a Service (SaaS) offerings such as Amazon Chime or WorkDocs. The more managed the service, the less security responsibility the customer holds. However, it’s never zero.
AWS is responsible for:
- Physical data center security
- Hardware and software infrastructure (physical infrastructure and compute, storage, networking)
- Global infrastructure, including Amazon regions and availability zones
- Managed service infrastructures are more conditional. They’re AWS’s responsibility when teams use managed services like Lambda, Fargate, or Amazon Relational Database Service (Amazon RDS).
AWS customers are responsible for:
- Data protection, including data security controls and data encryption
- Identity and access management (IAM roles, users, permissions, and identity federation)
- Application code and workloads
- Meeting compliance requirements for what’s deployed, including logging and monitoring using tools like AWS CloudTrail
- Network configuration (VPCs, subnets, security groups) are almost always the customer’s job, except in some highly abstracted SaaS service providers like Amazon WorkDocs, where network configuration isn’t exposed at all.
- Patching Amazon EC2 instances and self-managed services, when using EC2 or managing infrastructure. But on Lambda, Fargate, or RDS, AWS handles patching (though teams still patch dependencies in their code or containers)
- Logging and monitoring using tools like AWS CloudTrail (though AWS manages CloudTrail itself)
For AWS, shared responsibility shifts depending on the service: the more managed the service (e.g., Fargate vs. EC2), the more AWS handles behind the scenes, but in all instances, teams retain control of customer data and configurations in the AWS environment.
Runtime and Container Scanning with Upwind
Upwind offers runtime-powered container scanning features so you get real-time threat detection, contextualized analysis, remediation, and root cause analysis that’s 10X faster than traditional methods.
Get a DemoHow Unique is the AWS Model?
The AWS Shared Responsibility Model follows the same general principles of shared responsibility as other cloud providers, like Microsoft Azure and Google Cloud Platform (GCP), but it has a few unique characteristics that set it apart:
Service by Service Granularity
AWS offers a vast range of services from fully managed ones like Fargate and Lambda, to infrastructure-heavy options like EC2. And the Shared Responsibility Model varies per service.
- In EC2, customers are responsible for the OS, patching, and network config.
- In Fargate, AWS handles the host OS and runtime, and customers only manage the container image and config.
- In S3, customers manage data access, permissions, and encryption.
Configurability and Identity and Access Management (IAM)
AWS puts more control in the customer’s hands, and that’s especially true when it comes to IAM, security groups, and network configuration. That means misconfigurations are both more likely and more dangerous. Unlike some platforms that lock down defaults, AWS trusts customers to set their own.
Shared Responsibility for Security of and in the Cloud
AWS’s model is often cited because it draws a clear line between:
- Security of the cloud: AWS’s job, including hardware, global AWS infrastructure, and managed service underpinnings.
- Security in the cloud: The customer’s job, from what they deploy to how they configure it.
This phrasing has become a defining feature of AWS’s model and is widely adopted even outside AWS.
Unique Deployment Models
AWS’s edge and hybrid offerings (like Outposts, Snowball, or Local Zones) add complexity. It’s true that AWS’s model includes special cases where customers can manage infrastructure on-premises, but under AWS’s service terms. That blurs the shared responsibility boundary more than GCP or Azure typically do.
With hybrid or edge offerings, customers can be responsible for physical security, network integration, and some aspects of infrastructure. They’ll need to see posture scores and monitor for configuration drift, noting gaps might be different across cloud, edge, and hybrid environments.
Differences in Responsibility Across AWS Cloud Services
One of the most misunderstood aspects of AWS security is that the Shared Responsibility Model isn’t static. There’s no single AWS approach; rather, the model changes depending on the service. And that can be a challenge for organizations that need to know whether their cloud resources are protected.
Among recent significant breaches, no significant cloud incidents have been attributed to failures under a cloud provider’s responsibilities. The PowerSchool and Snowflake data breaches involved compromised credentials, while the 2024 Ticketmaster breach stemmed from a breach of a 3rd-party vendor — a database services provider. Maybe that’s why knowing what the shared responsibility model covers is key to protecting assets.
The more AWS manages for customers, as with Fargate and Lambda, the smaller their responsibility footprint. Yet, customer risk won’t disappear completely, even with these models.
Here’s what AWS and customer responsibilities look like on a service-by-service basis.
| Service | Who Manages the OS? | Who Secures the Runtime? | IAM Responsibility | Network Config Responsibility | Typical Blind Spots |
| EC2 | Customer | Customer | Customer | Customer | OS patching, inbound ports, SSH exposure, public IPs |
| ECS on EC2 | Customer | Customer | Shared (task roles by customer) | Customer | Insecure task definitions, broad IAM roles |
| EKS (Kubernetes) | Customer (for worker nodes) | Shared (control plane by AWS, nodes by customer) | Customer (Kubernetes RBAC and IAM integration) | Customer (VPC and network policies) | Overly permissive RBAC, lack of network segmentation |
| ECS on Fargate | AWS | Shared (customer responsible for app-level security) | Customer | Customer | Lack of runtime visibility, container image risk |
| EKS on Fargate | AWS | Shared | Customer | Customer | Lack of runtime visibility, container image risk, plus Kubernetes complexity |
| Lambda | AWS | AWS (execution environment), customer owns code-level risk | Customer | Customer | Insecure environment variables, excessive role permissions, poor input validation |
It’s important to note that while EC2 gives customers the most control, they’ll also take on the most responsibility. Fargate and Lambda reduce infrastructure overhead, shifting some responsibility to AWS, but as a result, teams get less insight and visibility into their infrastructure. EKS adds orchestration complexity, blending AWS-managed control planes with user-managed policies.
Regardless of service, IAM, access control, and network config are always the customer’s job.
Operationalizing AWS Security Across Services
Once teams understand their different responsibilities across AWS services, they’ll need to build workflows and tools to ensure their side of the model is both secure and visible. By treating the shared responsibility model like an operational control layer, they’ll be able to assign, measure, enforce, and audit their own security in these cloud services, and, ultimately, reduce response times.
Here are the steps:
1. Map ownership by service
In AWS, no two services share the exact same security footprint, so teams will need to map who owns what and do away with their blanket policies. EC2, for instance, requires patching, firewall configuration, and full operating system-level security. Fargate, on the other hand, abstracts the host, leaving organizations to secure the container image, IAM roles, and runtime behavior.
Without an explicit mapping of responsibility by service, teams may assume AWS is responsible for aspects of their own security that it is not. That’s a blind spot that can lead to breaches.
A CNAPP or CSPM can help surface all AWS services in use and assign asset-level ownership tags, like “Team: DevOps” or “Domain: IAM”. This visibility can fill gaps in coverage, especially as companies shift toward hybrid architectures or multi-account AWS setups where responsibilities vary even more.
2. Shift enforcement into CI/CD (But grounded in reality)
The earlier you catch misconfigurations, the cheaper they are to fix. But that only works when teams catch the right things and don’t get caught up in the noise. And unfortunately, many shift-left efforts flag every possible violation in IaC templates, without any sense of whether the misconfiguration is actually risky in practice. That leads to alert fatigue.
A more grounded approach brings runtime context into CI/CD, filtering misconfigurations through exposure, usage, and service-specific behavior. For example:
- In EC2, IaC policies might block public AMIs, enforce encryption on EBS volumes, or require patched OS baselines, helping teams manage the host and infrastructure.
- In Lambda, organizations can scan for hardcoded secrets or unencrypted environment variables in function configs, with runtime visibility to help prioritize only those tied to production roles or traffic-facing APIs.
- In EKS, security analysts might validate that every namespace has network policies or that RBAC roles don’t grant cluster-admin access by default, though runtime context would tell them which roles are actually in use.
- In Fargate, where AWS manages the host but customers still own IAM and container configs, checks that seem minor on paper (like missing resource limits or excessive task permissions) can become critical if the container is handling sensitive data or exposed to the internet.
Shift-left works best when it’s filtered through risk. That means combining static checks with dynamic signals like usage, exposure, identity, and intent.
3. Continuously monitor for drift
Even with perfect IaC, drift happens. That’s especially true when changes are made via the AWS console, CLI, or external automation. That’s where the Shared Responsibility Model can break: AWS won’t alert teams if their own IAM role is manually modified to allow *:*, or if a developer opens an S3 bucket to the world during troubleshooting.
Services like AWS Config, CNAPPs, or tools like Driftctl (an open-source drift control tool), can help detect when the actual cloud environment no longer matches the IaC. For instance, teams might see drift in ECS, where task definitions are modified outside of the GitOps pipeline, or in EC2 if SSH access is re-enabled manually after being disabled in code.
For teams, the bottom line is this: catch these moments early, because drift means an organization’s cloud is operating outside their defined responsibility boundaries. Even worse, no one may notice.
4. Correlate runtime behavior to config gaps
Security misconfigurations can feel abstract until they become attack vectors. For example, a Lambda function with excessive IAM permissions might seem harmless until runtime logs show it being used to enumerate Amazon S3 buckets it shouldn’t access. Or a container in Fargate might escalate privileges using a vulnerable base image and lateral movement via misconfigured VPC rules.
This is where CNAPPs with runtime visibility (especially those using eBPF or agentless runtime detection) excel: they connect what’s happening in production to the misconfigurations that allowed it, and some can feed that data back to the CI/CD pipeline for targeted improvements in future deployments.
Without this correlation, teams may be able to perform immediate fixes, like terminating processes, but they won’t fully address the root cause.
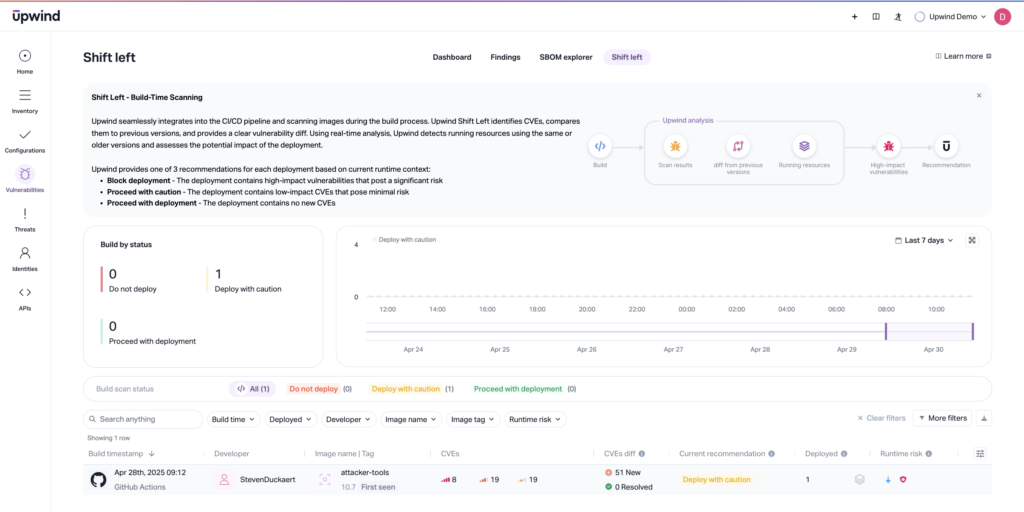
5. Route alerts to the responsible internal teams
Security teams often get alerts they can’t act on. Teams may see notifications like Kubernetes RBAC misconfigs that belong to the platform team, or CI/CD image scan failures that fall under DevOps.
Working out these workflows is increasingly important in multi-service environments. For instance, if EKS pods lack network policies, that alert should route to the Kubernetes admin, not a general cloud security team. If a Lambda function is using a role with admin access, the developer team needs to know.
One way to streamline workflows is by using CNAPPs, SIEMs, or ticketing systems with ownership-based routing logic (using asset tags, service metadata, or Terraform repo ownership) to avoid wasted time and dropped issues. Responsibility isn’t shared if no one knows it’s theirs, let alone which AWS account it lives in.
6. Revisit assumptions quarterly
Security strategies need to keep up with business decisions about cloud usage. For example, a team using EC2 today may migrate to Lambda next quarter. Or AWS may introduce new defaults, like stricter public S3 bucket settings, that shift some security responsibilities back to the provider.
Ultimately, it’s up to teams to stay on top of changes and protect their assets even as the environment shifts.
Hold quarterly or biannual shared responsibility reviews to be sure that documentation, certifications, and internal training reflect updated models. CNAPP reports can be a great tool to track which services are growing in footprint. Flag new services like Outposts or Snowball Edge that may reintroduce physical security or patching responsibilities to your team and foreground discussions on the responsibilities you may not have had to manage before.
The model isn’t just shared; it’s also shifting, so customers need to revisit the rules beyond the initial set-up phase.
Upwind Protects Workloads No Matter Where They Run
The shared responsibility model sets a clear boundary between what AWS secures and what customers must secure themselves, but those boundaries can shift dramatically based on the service, level of abstraction, and how teams configure and operate their cloud environments. And it’s easy for teams to assume AWS has their back, but later discover gaps like IAM, runtime visibility, and container misconfigurations.
Upwind closes those gaps, aligning customer responsibilities with real-time cloud activity. It brings runtime context into CI/CD pipelines so teams prioritize what matters early, detect drift, map risks to services like EC2, EKS, and Lambda, and enforce the right controls with ownership and clarity. When “of the cloud” and “in the cloud” are blurred, Upwind makes sure you’re still covered. Get a demo today.
FAQ
What does the Shared Responsibility Model look like for forensic investigation?
In a breach, the Shared Responsibility Model determines who has access to what data and which logs. In practice, that line can get blurry. Even if AWS secures the infrastructure, teams are responsible for proving whether a misconfiguration or exploit came from their side, and they’ll only have the evidence they choose to log. Here’s what to know:
- AWS provides logs for infrastructure events, including CloudTrail, VPC flow logs, and access to managed service actions
- Customers need to enable and retail logs. AWS won’t store them by default.
- Customers are responsible for detection and response
- Customers are responsible for misconfigured services like S3, IAM, or EC2
- AWS support won’t give deep packet data or workload forensics that customers are responsible for providing
How do hybrid and edge services like Outpost or Snowball complicate the Shared Responsibility Model?
Hybrid and edge services reintroduce physical infrastructure to customers. With services like Outposts and Snowball, teams won’t only configure the cloud, they’ll have to manage physical space, local compliance, and on-premise patching. Here are key details:
- Customers may be responsible for physical security
- Patching isn’t fully abstracted, as customers often manage operating systems or app-layer updates while AWS often handles firmware or base software
- Data residency and compliance are customer responsibilities and may include regulation requirements like HIPAA and GDPR
- Local access risks like local users, USBs, and offline mode can mean new attack vectors that weren’t an issue in cloud-native services
What are the most common misconceptions about the AWS Shared Responsibility Model?
Managed services don’t mean managed everything. AWS doesn’t secure the entirety of assets running on its cloud platforms in any service, and teams that understand that may still overestimate AWS’s role in securing the surface area they’ll need to configure, deploy, and expose. Where does risk live? That’s the most common misunderstanding once teams recognize they share some level of risk.
- Patching is often misunderstood, since some services handle some patching responsibilities. In EC2, the customer handles OS and app updates.
- IAM misconfigurations are common, and AWS provides tools to help, but it does not enforce least privilege.
- Runtime visibility doesn’t come with AWS models, and AWS won’t alert teams if a container runs with root or if a Lambda is over-permissioned.
- Network controls like VPC, security groups, and internet gateways are fully customer-managed.
- Compliance enforcement isn’t automatic. Customers need to set up monitoring, make sure they’re flagging violations, remediate them, and keep logs.
How does the Shared Responsibility Model break down in multi-account, multi-cloud environments?
With one cloud provider, one account, and one separation of powers, the Shared Responsibility is simple and straightforward. With multi-account AWS setups and multi-cloud strategies, it’s more challenging. After all, teams that account for the gaps they’ll need to cover in one model may find their policies aren’t applied consistently across accounts. Fragmentation makes it harder to track and enforce responsibilities, no matter what they are. Some key considerations for teams include:
- Decentralized ownership needs a plan: Teams need to know who owns resources, IAM roles, and misconfigured buckets.
- Inconsistent tools lead to blind spots: Is there an overall spot to monitor all resources?
- Shadow deployments are a risk: Is there centralized control to ensure resources aren’t spun up outside of pipelines or policies? Can teams detect them?
- Duplication is inefficient: Every account requires logging, policy, and enforcement setup.
- Compliance is a must: Maintaining the same policies across accounts is key, and that often means issues handling logs, controls, and responsibilities across platforms, too.
How does the Shared Responsibility Model apply to third-party vendors running on AWS?
When it comes to managed databases or SaaS tools, teams add another layer of responsibility on top of AWS’s. Teams are responsible for how vendors integrate into their cloud environments. That means responsibility is shared across parties, with the vendor offering the service. Cloud customers still need to manage data, configurations, compliance, and access.





