

Based on the widely used MITRE ATT&CK framework, MITRE ATT&CK Evaluations are independent tests for security tools that detail how they perform — not in theory, but under pressure. However, this test-optimized detection isn’t a perfect failsafe. But what is it? When does it make sense, and what’s missing? This article breaks down what MITRE ATT&CK Evaluations are, why they matter for security teams and decision-makers, and deeper issues teams need to know.
What Is A MITRE ATT&CK Evaluation?
A MITRE ATT&CK Evaluation is an independent assessment of cybersecurity vendors using real-world adversary techniques compiled by the MITRE organization.
They’re controlled, repeatable exercises run by MITRE Engenuity, a non-profit arm of MITRE. MITRE simulates the exact attacker playbook that a real cyber attacker might use across vendor tools to evaluate detection. Vendors participate voluntarily, and results are published. Evaluations are identical across vendors. Here’s the methodology used in evals:
- Adversary Emulation Planning
MITRE selects a known threat group, like APT29 or FIN7, and builds a step-by-step emulation plan using real-world TTPs from the ATT&CK framework. Each emulation covers the full kill chain, from initial access to command and control. - Test Environment Setup
MITRE deploys a controlled enterprise environment designed to reflect typical infrastructure — complete with endpoints, servers, and user accounts. Vendors participating in the evaluation install their security solutions and configure them according to standard deployment guidelines (with no post-facto tuning). - Execution of Simulated Attacks
MITRE executes the multi-stage attack scenario across the environment using emulated tools, malware, and techniques attributed to the selected threat actor, for example, a ransomware attack on an endpoint. Every technique is executed deliberately and reproducibly, ensuring fairness and transparency across vendors. - Data Collection & Visibility Mapping
Throughout the attack simulation, MITRE records how the vendor’s product responds to each step: Was the behavior detected or missed? Was it telemetry-only (raw data) or analytically correlated (high-fidelity alert)? Was the detection delayed, real-time, or contextualized?
- Results Documentation & Reporting
MITRE publishes vendor-specific results in the form of interactive matrices, showing technique-level detection fidelity, coverage gaps, and correlation capabilities. Importantly, no scoring or ranking is assigned — the data is left open for interpretation based on an organization’s priorities.
Not all security vendors participate, and MITRE doesn’t conduct testing on all tool types. Participants are mostly endpoint and detection-focused tools: Endpoint Detection and Response (EDR), Extended Detection and Response (XDR), and Next-Generation Antivirus (NGAV) are included.
Security Information and Event Management (SIEM) and cloud native application protection platforms (CNAPP) aren’t directly tested, but SIEM results may emerge based on integrations. Cloud-focused evaluations for CNAPP tools are in the works.
Let’s look at the steps more closely:
| MITRE Step | What Happens | What to Ask | What’s Missing | CNAPP Adds |
| Adversary Emulation | MITRE simulates a real threat group’s tactics. | Does this reflect the cyber threats we face? | One APT only; skips cloud-native, identity-based threats. | IAM abuse, misconfigurations, cloud-native techniques. |
| Environment Setup | Tools deployed in a clean, test environment. | Will it work the same in our cloud/hybrid stack? | Optimized setups are not real-world conditions. | Asset visibility across cloud and shadow infrastructure. |
| Attack Execution | Step-by-step attack run identically across tools. | Can it detect variations, not just known playbooks? | Hardcoded detections can mask weak behavioral coverage. | Runtime threat detection in dynamic environments. |
| Data Collection | MITRE tracks detection type and context. | Are alerts actionable — or just noise? | Raw logs are not the same as correlated threats. | Threat graphs showing impact and blast radius. |
| Results Reporting | MITRE publishes detailed, no-score matrices. | Can I actually use this to make buying decisions? | Vendors cherry-pick stats, hide weak context. | Prioritized, contextual dashboards tied to real risk. |
Runtime and Container Scanning with Upwind
Upwind offers runtime-powered container scanning features so you get real-time threat detection, contextualized analysis, remediation, and root cause analysis that’s 10X faster than traditional methods.
Why MITRE ATT&CK Evaluations Matter for Cybersecurity
MITRE ATT&CK Evaluations were created to address a growing problem in cybersecurity: too many vendors claim they detect threats, but few can prove it in realistic attack conditions.
Cyber attacks have increased 30% each year over the last 5 years, making detection more pressing than ever.
Detecting attacks quickly can make the difference between an attack that’s handled easily and one in which adversaries spend time within organizational networks, finding and exfiltrating sensitive data and intellectual property, causing large-scale breaches and slashing customer trust.
Ultimately, the purpose isn’t to “pick a winner” among vendors participating in the MITRE evaluation but to enable smarter, more strategic investments in security tooling. It’s about having a transparent, standardized lens for understanding how each vendor performs in the face of adversaries that mirror the threats companies could face at any time in the current threat landscape.
For CISOs, security architects, and SOC leaders, these evaluations offer a unique opportunity to benchmark capabilities, identify blind spots, and make evidence-based purchasing and configuration decisions.
There are concrete benefits to evaluation.
Standardized Testing
Vendors are tested under identical scenarios, so it’s simple to compare their performance. The process is rigorous and transparent.
Real-World Attack Simulation
Evaluations use actual techniques observed in the wild by cybercriminals. They’re not artificial or hypothetical.
Tactics, Techniques, and Procedures (TTP)-Level Visibility
Evaluations track detections, showing what was caught and what was missed. A MITRE evaluation traces multiple TTPs across surfaces.
Transparent and Public Results
All detections, be they accurate, missed, or delayed, are published so independent organizations and teams can analyze findings.
Detection Context Beyond Yes or No
Evaluations show whether detections are general or specific and whether they include useful analysis. For example, a tool may detect that an email attachment was opened (general), but it may go beyond, detecting that an email user opened a malicious Excel file that downloaded a payload from a known C2 domain.
Correlated Alert Quality
Evaluation helps buyers see if tools correlate steps in an attack into useful and actionable chains.
SOC Relevancy
Evaluations show how tools can support analyst workflows, elucidating speed of detection but also labeling, and how they present clear paths for containing threats.
Limits of MITRE ATT&CK Evaluations
MITRE’s endpoint-focused ATT&CK evaluations are useful, but they aren’t a cure-all for organizations wanting the best threat detection.
Cloud and Identity-Aware Gaps
MITRE ATT&CK evaluations often skip identity-driven or cloud-native techniques like misconfigured S3 buckets or exfiltration through cloud storage or APIs.
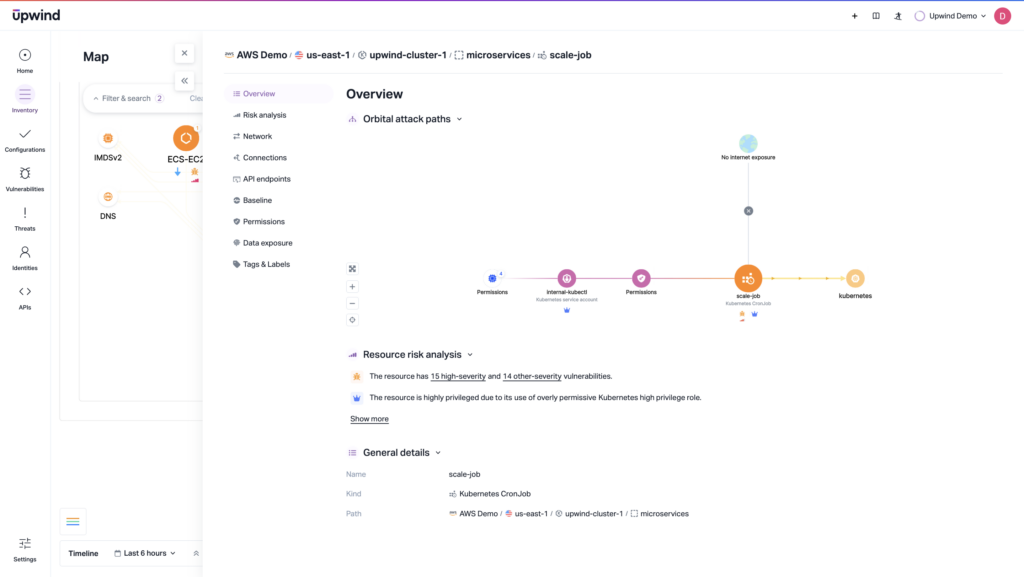
Fragmented Alerts
MITRE shows whether a vendor detects each step of an attack, but not whether it correlates them into a cohesive incident for analysts. Want to understand the blast radius in real time? That’s not necessarily information an evaluation can offer.
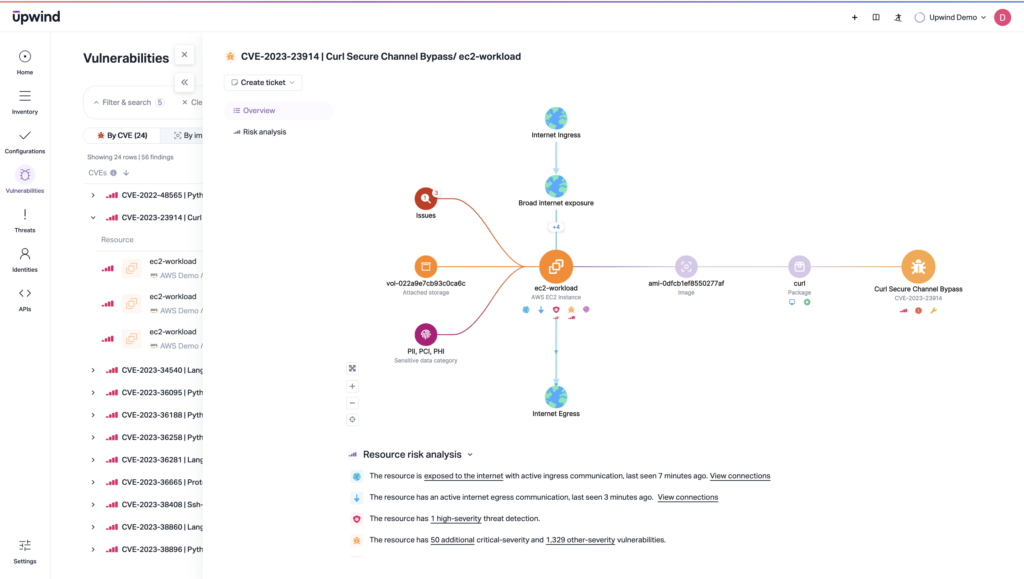
Runtime Blind Spots
What happens when the attacker doesn’t follow a known APT playbook? MITRE focuses on known, repeatable behaviors. CNAPPs can detect novel or unknown runtime events that are beyond the scope of signature-based endpoint tests.
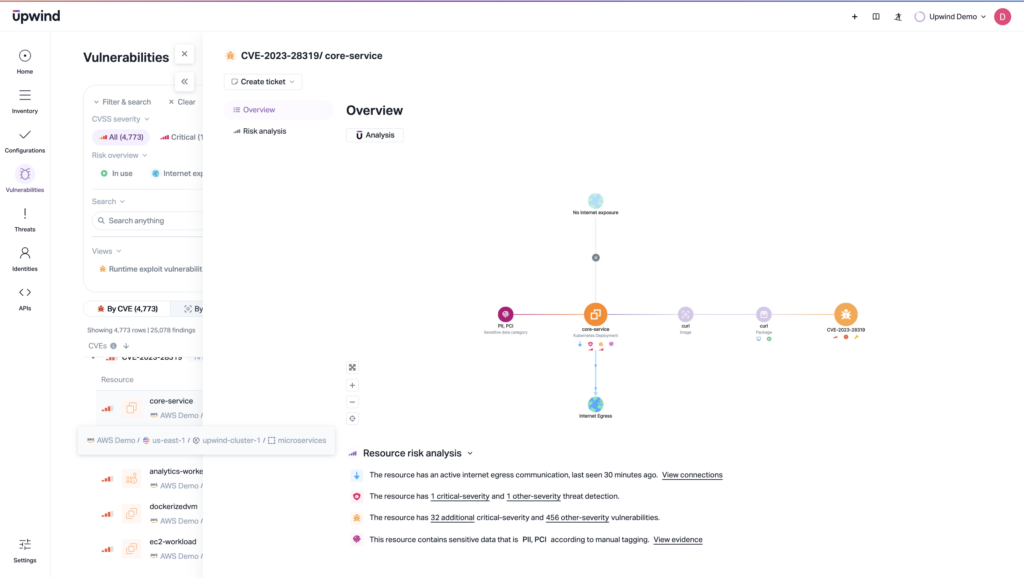
Visibility Across Environments
MITRE assumes full visibility into the test ecosystem in production. Shadow IT, disconnected tools, or unmanaged assets mean that real blind spots exist. In the end, MITRE scores can’t help if your tool can’t see the whole environment.
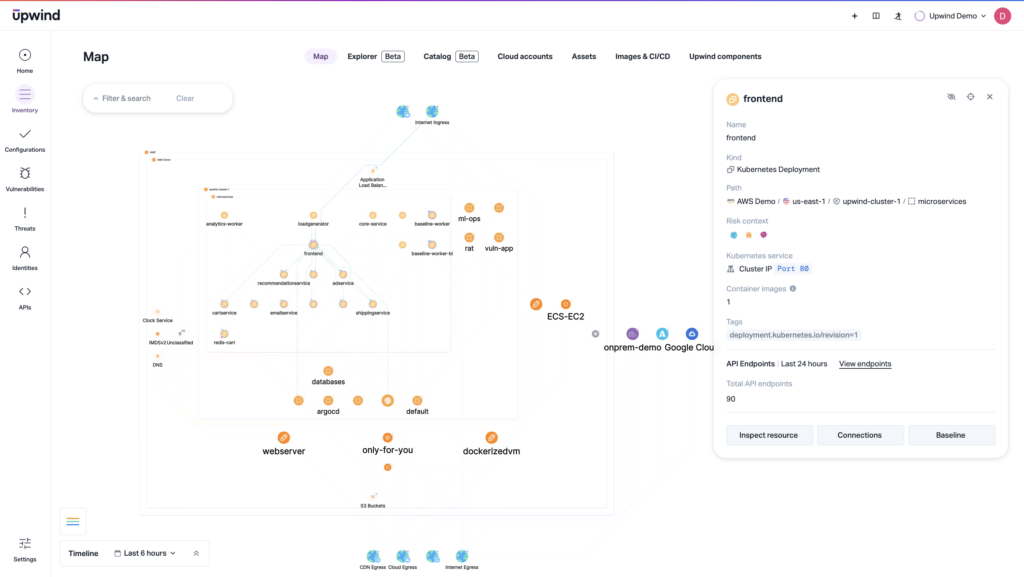
Configuration and Response Gaps
MITRE evaluations show which tools detect threats. But it doesn’t show which tools prevent or fix them. Vendors that shine in MITRE evaluations for detecting lateral movement may still allow the action to succeed. Can a tool stop the threat, or just tell teams they’re compromised? Further, can it fix the problem in real-time, such as making configuration changes, before damage is done?
Evaluating MITRE ATT&CK Evaluation Results
In spite of limitations, MITRE ATT&CK Evaluations help validate whether a cybersecurity solution provides the depth and visibility needed across the attack lifecycle, from initial access to exfiltration. They highlight whether a tool generates actionable alerts or just logs raw telemetry. That’s a big bonus for security teams trying to reduce dwell time, improve response speed, and prioritize signal over noise.
From a SOC perspective, the evaluations show which vendors excel at correlating signals across techniques, how they handle chained attacks, and whether their detections are enriched with context (e.g., linking privilege escalation to a specific identity or process). These details matter when assessing whether a product will help analysts detect stealthy threats or bury them in uncorrelated data.
Key Insights to Watch For from Results
Not all detections are equal. One of the most valuable insights from MITRE Evaluations is understanding how detections are surfaced. Are they real-time? Are they correlated? Are they buried in logs or visible in dashboards?
Evaluations provide:
- Telemetry: Raw data logged, but not necessarily correlated into an alert.
- General Detection: A generic alert that something suspicious occurred, with limited context.
- Tactic/Technique Detection: Accurate alerting mapped to a specific tactic or technique (e.g., Credential Dumping).
- Delayed Detection: Detection occurred but was not in real-time, which may affect response capability.
Look for:
- Alert fidelity: Does the tool produce high-confidence, actionable alerts tied to specific tactics?
- Technique coverage vs. tactic coverage: Some vendors detect broad categories; others pinpoint the exact technique used.
- Detection depth: Was the alert enriched with process, user, or network context?
- Visibility gaps: Where does detection fall off: initial access, lateral movement, data exfiltration?
Results are not a scorecard, but a way to match vendor capabilities with internal detection requirements, use cases, and team maturity. For example, a vendor that detects 100% of techniques isn’t necessarily better if those detections are buried in uncorrelated telemetry.
While MITRE avoids vendor scoring to maintain neutrality, several performance indicators can help guide evaluations. Focusing on metrics that speak to operational value and strategic alignment is important:
- Detection Coverage: Total number of techniques detected, broken down by tactic (e.g., Initial Access, Lateral Movement, Exfiltration).
- Analytic vs. Telemetry Ratios: High analytic detection rates mean fewer raw signals for analysts to interpret manually.
- Correlation Depth: Can the tool link seemingly separate events into a coherent attack story?
- Real-Time Response Capabilities: How many detections occurred at the moment of execution versus delayed analysis?
- Contextual Enrichment: Does the detection include useful metadata like process lineage, user identity, or network flow?
Comparing vendors based solely on “how many detections” they had is misleading. A product that logs every event without context or correlation might detect more, but offer less real-world value to security operations. The right way to compare vendor performance is to ask:
- Which tools produce high-fidelity alerts that reduce analyst workload?
- Do vendors provide tactic-level or technique-level granularity?
- How well does the tool perform across the full attack lifecycle, not just initial access or execution?
- Does it detect stealthy behavior like credential access or defense evasion?
- How much manual effort is needed to interpret the output?
Using Evaluations to Strengthen Security
By comparing how each vendor performs across attack stages: Initial Access, Privilege Escalation, Lateral Movement, and Exfiltration, companies can then prioritize solutions that close visibility gaps where they’re most vulnerable.
Avoiding Misleading Vendor Claims
Security vendors often cherry-pick their performance in MITRE ATT&CK Evaluations to appear stronger than they are. Marketing claims might highlight “100% detection coverage” or “full tactic visibility”, but those numbers rarely tell the whole story.
To avoid being misled, some tips include:
- Looking beyond raw detection counts. High detection numbers don’t mean high-fidelity alerts.
- Distinguishing between telemetry and analytic detection. Only the latter provides meaningful, actionable insights.
- Checking for delayed detections. Real-time visibility is critical for stopping fast-moving attacks.
- Watching for coverage drop-off after initial access. Some tools perform well at the front of the kill chain but miss deeper activity.
It’s important to evaluate vendors based on how well their detections match operational realities, not just being lured by marketing spin.
Managing Implementation
Beyond the results themselves, buyers need a tool that can detect attacks, but they also need to configure it so it does so consistently and within an organization’s environment.
Best practices include:
- Tuning detections based on MITRE priorities. If the evaluation shows gaps in lateral movement, companies can work with the vendor to enable or improve those rules.
- Integrating MITRE mappings into detection engineering workflows. Using the ATT&CK Navigator to overlay results onto current detection stacks is worthwhile.
- Testing detections regularly. Exercises like purple teaming and emulation frameworks (e.g., Atomic Red Team) can simulate tactics that the vendor should catch.
- Involving the SOC early. Making sure the solution’s detections align with existing alert triage processes helps to avoid creating noise or alert fatigue.
MITRE Evaluations are for more than just procurement. They’re a living reference point to shape, test, and evolve detection and response postures over time.
The Future of MITRE ATT&CK
MITRE ATT&CK has already reshaped how security teams think about adversary behavior, shifting the industry toward technique-level detection and threat-informed defense. But the future of MITRE ATT&CK, especially its evaluations, will need to keep pace with cloud-native attacks, identity abuse, and cross-domain threats that don’t neatly fit into endpoint security models.
MITRE is already expanding into ICS, cloud, and enterprise matrices, and the evaluations themselves are beginning to incorporate more complex, multi-environment attack flows that reflect how real adversaries operate today.
MITRE may bring in more incident response effectiveness to evaluations, not just detection fidelity, to offer a more complete view of how security tools contain and remediate threats in real-world timelines. This means MITRE ATT&CK will likely only grow in strategic value, as both a planning tool for threat modeling and a validation mechanism for tooling and team readiness.
Upwind’s Runtime Security Complements MITRE Security
MITRE ATT&CK evaluations continue to expand, now touching on cloud and container techniques, but they have yet to fully capture the granular realities of cloud runtime environments, where risks emerge dynamically and the traditional kill chain blurs. This isn’t a shortcoming of MITRE. Rather, it’s a reflection of how new and complex the runtime cloud threat surface is.
Attack paths in these environments involve ephemeral workloads, identity misuse, exposed APIs, and lateral movement across cloud services; all areas that are still evolving in both adversary tactics and defensive modeling.
“You need something that can learn your system, learn what’s normal, what’s abnormal, what’s within the bounds of normal – and say I think you might have a problem over here, you should go look into it. That’s not something that most traditional security tools were built to do.”
-Joshua Burgin, CPO, Upwind
Upwind offers a powerful complement to the ATT&CK-driven approach: by delivering real-time, context-rich protection of cloud workloads at runtime, it addresses threats that aren’t always reflected in today’s evaluation scopes. Get a demo.
FAQ
Is MITRE a contractor?
Not exactly. MITRE is a non-profit organization that operates federally funded development centers in the US. That means it works for the public interest. It’s technically a government contractor, but it’s not a contractor in the traditional sense that organizations can buy its products or services.
Further, MITRE doesn’t profit from vendor endorsements or commercial evaluations. Instead, MITRE Engenuity ATT&CK Evaluations are collaborations without a profit motive or competing interests.
What is a CVE in MITRE?
Common Vulnerabilities and Exposures (CVEs) are the unique IDs assigned to publicly known software vulnerabilities. MITRE owns and operates the program that catalogues CVEs. That means it:
- Hosts the database that houses CVEs
- Assigns ID codes to CVEs
- Standardizes descriptions, affected products, and other information about vulnerabilities
CVEs are the vulnerabilities used by attackers to penetrate corporate computing systems. MITRE tracks CVEs, but it also tracks the behaviors that attackers use to exploit them.
What about Linux?
The role of Linux in MITRE ATT&CK Evaluations is smaller than you may expect, and that’s a limitation worth knowing. First, MITRE evaluations are often Windows-based. Evaluations are commonly conducted in Windows-heavy enterprise environments, using endpoints and user accounts configured in Microsoft.
MITRE does have a Linux ATT&CK Matrix, but it’s rarely the focus of evaluations. That’s because Linux detection, even from vendors of EDR and XDR that claim Linux support, can be limited and poorly contextualized.
What about Managed Services?
Managed services (like MDR, MSSP, or MDR-over-XDR offerings) are often left out of or underrepresented in MITRE ATT&CK Evaluations, which is a key blind spot for teams that rely on outsourced detection and response.
MITRE tests technologies, not the people behind them. It’s about tool capabilities, so the effectiveness of a 24/7 SOC, threat hunting team, or response process won’t be represented in results.
If a security service provider uses one of MITRE’s vendors, will the MITRE results reflect those that the organization gets?
Maybe. Results will be dependent on the teams’ ability to act on results, act quickly, and enrich results with context.
MITRE did launch a managed services evaluation in 2022, but adoption remains slim, making it hard to compare services.





