io_uring: Linux Performance Boost or Security Headache?


The Linux kernel is constantly evolving, and one of the significant additions in recent years is io_uring. Introduced in kernel 5.1 (2019), it’s designed to dramatically speed up input/output (I/O) operations. But as with many powerful tools, it brings new security considerations. Let’s break down what io_uring is, the risks it presents, and how to approach securing it.
What is io_uring?
At its core, io_uring is a modern interface for asynchronous I/O (AIO) in Linux. Developed by Jens Axboe, it aims to overcome the performance bottlenecks and limitations of older AIO methods and traditional blocking I/O. It achieves this primarily through:
- Shared Ring Buffers: It uses two main shared memory rings – a Submission Queue (SQ) and a Completion Queue (CQ) – for communication between an application (user space) and the kernel. This minimizes the need for slow data copying.
- Reduced System Calls: Applications can batch multiple I/O requests (Submission Queue Entries or SQEs) into the SQ and notify the kernel with fewer system calls (like
io_uring_enter), or even potentially zero calls in polling mode
The result? Faster, more efficient I/O, especially beneficial for high-throughput applications like databases and web servers
2. Offensive Capabilities: The Attacker’s Angle
The very design that makes io_uring fast also makes it interesting to attackers. Because it bypasses the traditional system calls for many I/O operations (like file reads/writes or network sends/receives), it can be used as an evasion technique.
Some demonstrations of this potential were shown in proof-of-concept malware. Such demonstrations show how io_uring could be used for core malicious functions, like communicating with a command-and-control (C2) server and executing commands, specifically avoiding the standard syscalls that many security tools monitor. This allows malware to operate more stealthily on a compromised system. With over 61 different operation types supported, io_uring offers a broad surface for potentially malicious actions beyond simple I/O.
Copied
This evasion potential is compounded by io_uring‘s history as a significant source of kernel vulnerabilities since its introduction. Its complexity has led to numerous bugs, many allowing local privilege escalation (LPE), such as issues involving improper memory handling (like CVE-2021-41073) or out-of-bounds access (like CVE-2023-2598). Google even reported that 60% of kernel exploits submitted to their bug bounty in 2022 targeted io_uring, leading them to disable it by default in some environments. This underscores the need for careful risk assessment and robust, modern monitoring techniques when dealing with io_uring.
3. Why is io_uring Risky for Security?
The primary risk stems from its ability to sidestep conventional monitoring methods. Many security solutions, including Endpoint Detection and Response (EDR) tools, heavily rely on intercepting specific system calls (read, write, sendmsg, recvmsg, accept, etc.) to observe program behavior and detect threats
When an application (or malware) uses io_uring to perform these actions via SQEs processed asynchronously by the kernel, the traditional syscall hooks might never be triggered. This creates a significant blind spot. The Curing PoC showed that popular tools relying solely on this syscall hooking could fail to detect malicious network and file activity performed via io_uring.
4. How Can We Detect Malicious io_uring Use?
Detecting malicious io_uring activity requires looking beyond traditional I/O syscalls. Strategies include:
LSM Hooks / KRSI: Points within the Linux Security Module framework where security decisions are made. Kernel Runtime Security Instrumentation (KRSI) is a framework specifically designed to leverage eBPF with LSM hooks for better security observability. This provides a more robust way to see the effects of io_uring operations.
- Monitoring Setup: The
io_uring_setup(2)syscall is required to initializeio_uring. Detecting this call, especially from unexpected processes, can be an initial flag. - Anomalous Usage Detection: Since
io_uringisn’t used by most standard applications, its use by an unexpected process can be highly suspicious. Baselining normal behavior and alerting on deviations is key. - Deep Kernel Visibility (eBPF): Extended Berkeley Packet Filter (eBPF) allows for deeper, programmable kernel instrumentation. By attaching eBPF programs to:
- Kprobes: Dynamic probes attached to kernel functions, potentially within the io_uring subsystem itself.
- LSM Hooks / KRSI: Points within the Linux Security Module framework where security decisions are made. Kernel Runtime Security Instrumentation (KRSI) is a framework specifically designed to leverage eBPF with LSM hooks for better security observability. This provides a more robust way to see the effects of io_uring operations.
Copied
5. Important Considerations
While io_uring presents evasion risks, it’s not an automatic “invisibility cloak”:
- Initial Access Needed: Attackers must first compromise the system before they can use
io_uringfor evasion. Detection opportunities exist before this stage. - Setup is Observable: As mentioned, the
io_uring_setupcall itself can be monitored. - Not All Activity is Hidden: Actions like process execution (
execve) still use traditional syscalls and remain visible. File Integrity Monitoring tools usingFANOTIFYare also reportedly unaffected. - Seccomp Blocking: In many container environments (like default Docker), security profiles (
seccomp) often block theio_uring_setupsyscall by default, preventing its use unless explicitly allowed. - Vulnerability Surface:
io_uringis complex and has had a significant history of security vulnerabilities since its introduction, many leading to Local Privilege Escalation (LPE). Google noted that 60% of kernel exploits submitted to their bug bounty in 2022 targetedio_uring. This means attackers might exploitio_uringbugs to gain privileges before using it for evasion.
6. How Upwind Tackles the io_uring Challenge
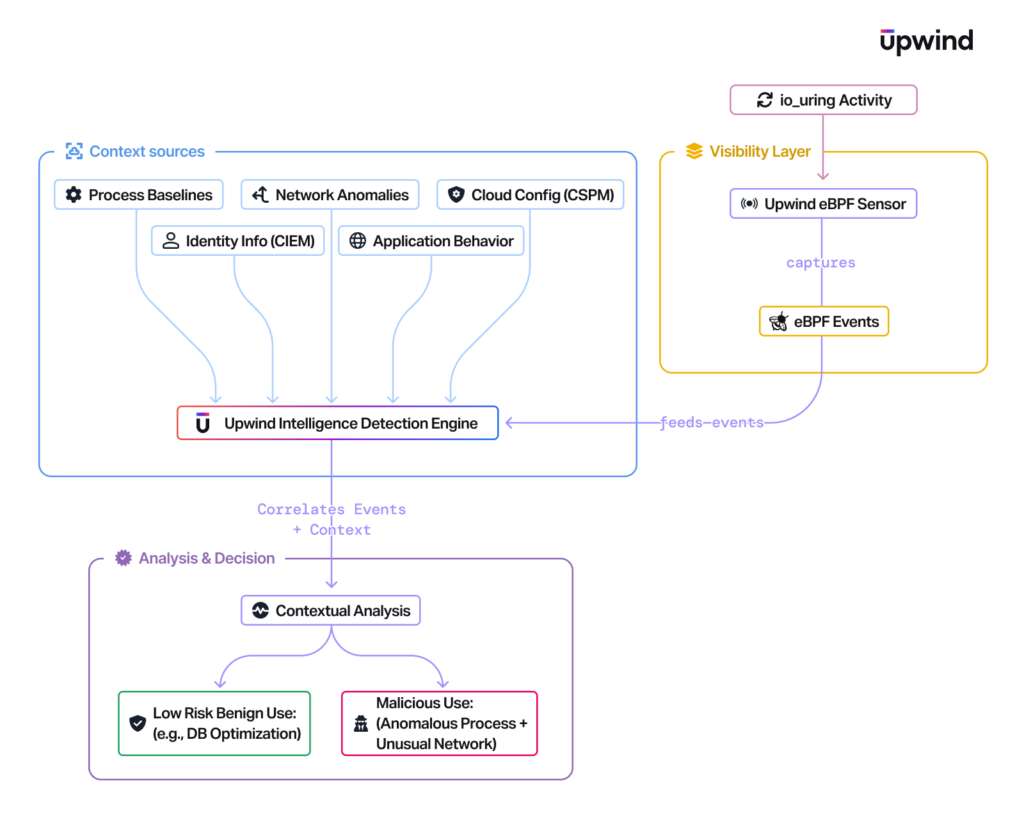
Modern security platforms need to adapt to interfaces like io_uring. Upwind approaches this challenge by combining deep visibility with contextual analysis:
- eBPF for Deep Visibility: Upwind utilizes an advanced eBPF-based sensor to gain deep, real-time visibility directly within the kernel. This modern approach allows monitoring that goes significantly beyond traditional syscall interception, enabling observation of kernel-level activities, including potentially relevant
io_uringsetup calls and other kernel events captured through eBPF’s instrumentation capabilities. This comprehensive kernel-level insight is crucial for understanding the full picture of system behavior. - Runtime Context is Crucial: Simply detecting io_uring usage isn’t enough, as legitimate applications use it for performance. Upwind correlates data across multiple dimensions in real-time: low-level system activity (syscalls, process behavior), application behavior, API interactions, network flows, cloud infrastructure configurations, and identity information.
- Intelligent Differentiation: By building this rich runtime context, Upwind aims to intelligently distinguish between legitimate
io_uringuse by expected high-performance applications and suspicious or anomalous usage indicative of an attack. This contextual analysis helps reduce alert fatigue and allows security teams to focus on credible threats.
Conclusion
io_uring is a powerful performance enhancement for Linux, but its ability to bypass traditional syscall monitoring presents a real challenge for security. Defending against potential misuse requires moving beyond simple syscall hooking and embracing deeper kernel visibility techniques like eBPF. Furthermore, context is paramount – understanding who is using io_uring and how it fits into the broader system activity is key to separating malicious abuse from legitimate optimization. As Linux continues to evolve, our security tools and strategies must evolve with it.




